【IT168 显卡频道】回望过去,整个DirectX9时代对于ATI来说是几经波折的,有着Radeon9000系列的凯歌,也有着RadeonX1000系列的悲哀。而进入DirectX10时代,经历RadeonHD2000系列的挫折后,属于ATI的那片天空彻底黑暗了...即使我们还记得它是一支勇敢的红色大军,但彻底胜利的美酒对于红色大军来说是显得如此的奢侈。其实我们每一个玩家抚心自问,近年每次ATI发布的新一代产品,谁不总是从心底里面企盼着ATI能上演一场真正胜利的反击战?而这次机会真的来临了,RadeonHD5870携DirectX11将为ATI开启胜利之门……

第一章:Microsoft DirectX 11 API全解析
第一节:DX11吹来新春风?从DX10的架构特性说起
第二节:DirectX 11的前奏:尴尬的DX10.1
第三节:RV870的尚方宝剑:DirectX 11
第四节:第五代!Shader Model 5.0详解
第五节:Tessellation:可编程式拆嵌细分曲面技术
第六节:DirectCompute 11在游戏技术中的应用
第二章:ATI RV870人无我有的独门绝技
第一节:视觉无极限:ATI Eyefinity技术
第二节:透过RV870看今天的ATI Stream
第三节:加强版的UVD2.0:双1080P视频流
第四节:Win 7+全新Catalyst = 20%效能提升
第三章:ATI RV870图形芯片架构全解析
第一节:ATI的Sweet Spot策略
第二节:RV870架构解析:Radeon HD 5870的绝密武器之一
第三节:RV870架构解析:Radeon HD 5870的绝密武器之二
第四节:Radeon HD 5870/5850规格参数
第五章:ATI Radeon HD5870显卡性能测试
第一节:我们的测试平台
第二节:HD5870 v.s. HD4890
第三节:HD5870 v.s. HD4870 X2
第四节:HD5870 v.s. HD5870 CF
第五节:HD5870 v.s. GTX285
第六节:HD5870 v.s. GTX295
第六章:参测显卡性能汇总
第一节:OpenGL游戏——深入敌后之雷神战争
第二节:DirectX 9游戏——求生之路
第三节:DirectX 10游戏——孤岛危机之弹头
第四节:DirectX 10游戏——孤岛惊魂2
第五节:DirectX 10游戏——超级房车赛之起点
第六节:DirectX 10.1游戏——潜行者之晴空
第七章:完美无暇!无懈可击!你根本无法理解这张显卡如何设计出来的!
DX11吹来新春风?从DX10的架构特性说起
2006年11月,nVIDIA推出惊世骇俗的GeForce 8800 GTX为我们带来了前所未有的DirecX 10 Class GPU。随后ATI推出的Radeon HD 2900XT、Radeon HD 3870以及Radeon HD 4870等等全系列产品,更是将大众对于DirectX 10的渴望和期盼推向极致。大众对于DirectX 10的渴望不仅仅在于它带来的统一渲染,更重要的是,它还为众多的游戏开发者提供了更宽松的编程环境,给玩家带来了更逼真的画面质量。
较之以前,DX10的架构特性
DirectX之所以在广大的开发者中流行,是得益于它的简单易用和丰富的功能特性。然而,DirectX一直被一个主要的问题所困扰,那就是高CPU负载。
每次DirectX从应用程序那里接收到一条命令,它就需要先对这条命令进行分析和处理,再向图形硬件发送相对应的硬件命令。由于这个分析和处理的过程是在CPU上完成的,这就意味着每一条3D绘图命令都会带来CPU的负载。这种负载给3D图象带来两个负面影响:限制了画面中可以同时绘制的物体数量;限制了可以在一个场景中使用的独立的特效的数量。这就使得游戏画面中的细节数量受到了很大的限制。而使图像具有真实感的重要因素,偏偏是细节量。

Microsoft DirectX 10 Flight Simulator
较之之前任何版本的DirectX,DirectX 10的一个主要目标就是降低CPU负载。它主要通过三个途径来达到这个目的:第一,降低绘制消耗。它通过修改API核心,使得绘制物体和切换材质特效时的消耗降低;第二,降低CPU依赖。引入新的机制,降低图形运算操作对CPU的依赖性,使更多的运算在GPU中完成;第三,批量绘制。使大量的物体可以通过调用单条DirectX绘制命令进行批量绘制。下面我们就来仔细的看一下这三种方式:
1.降低绘制消耗
第一种方式的一个重要例子就是DirectX 10中对三维数据和绘制命令进行验证过程的修改。所谓三维数据和命令的验证,是指在DirectX绘制图形之前,对传给它的图形数据和绘制命令进行格式和数据完整性的检查,以保证它们被送到图形硬件时不会导致硬件出问题;这是很必要的一步操作,但是不幸的是它会带来很大的性能开销。

从上表我们可以很容易的看出,在DirectX 9中,每次绘制一帧画面之前,都会对即将使用的相关数据进行一次验证。而DirectX 10中,仅当这些数据被创建后验证一次。这很明显是可以大大提高游戏进行中的效率的。
2.降低CPU依赖性
在降低CPU依赖性方面,DirectX 10 引入的三个重要机制就是:纹理阵列(texture arrays)、绘制预测(predicated draw)和数据流输出(stream out)。
3.批量绘制
在DirectX 9中,对渲染状态的管理一直是一个十分消耗CPU时间的操作。所谓渲染状态,是指显卡进行一次绘制操作时所需要设置的各种数据和参数。例如,要绘制一个人物角色,就需要先设置他的几何模型数据的数据格式、纹理过滤模式、半透明混合模式等等——每设置一项,都要调用一次DirectX API,占用大量CPU时间,极大的约束了渲染的性能。

DX 9/DX10画质对比
为了使这些操作能够批量的进行,DirectX 10中引入了两个新的结构——状态对象(state object)和常量缓冲(constant buffers)。

DX 9/DX10画质对比
在DirectX 10中,可以先把树、草的几个模型设给显卡,然后将所有要画的树木的位置、方向和大小一次性的写入到常量缓冲(Constant Buffer)中,然后告诉DirectX——画!显卡就一下把所有的树木和草都一起绘制出来了!只有这样,像时下流行的Crysis,Far Cry 2等等游戏,才有可能渲染出如此逼真的森林效果。
DirectX 11的前奏:尴尬的DX10.1
如果说GPU PhysX是nVIDIA GeForce显卡的独有物理加速技术,那么DirectX 10.1只能说是ATI Radeon显卡提供的一种特色技术。为什么不能说这是ATI独有呢?事实上,DirectX 10.1图形芯片市场并非AMD-ATI独占,VIA-S3的Chrome 400系列也是支持DirectX 10.1的,但是由于其驱动不稳定、性能低下、贴图错误等等原因,难以得到消费者认可,故市面上大量存在的DX10.1显卡仅仅是ATI的Radeon HD 3xxx和4xxx系列显卡。

采用RV770核心的Radeon HD 4870
从Radeon HD3800到Radeon HD4800,AMD-ATI最大的一个技术亮点就是率先支持微软DirectX 10.1。但受限于上游硬件厂商间的角力,DirectX 10.1的推广并不是一帆风顺。对用户来说,再好的技术若没有游戏和驱动来配合,都是空谈。DirectX 10.1也是一样,虽然最关键的驱动可以搞定,但是少有游戏厂商的广泛支持,不可谓不是“巧妇难为无米之炊”。

ATI Radeon HD 3xxx和Radeon HD 4xxx显卡均支持DirectX 10.1
充满阻力的DirectX 10.1
客观上讲,DirectX 10.1新增加的内容对画质的提升不算太大,一些原本在DirectX 10中定为可选的特性规定为强制特性,如将16位浮点纹理过滤升级为32位,4x MSAA多重采样反锯齿等。因这种情况,ATI虽然自HD3000系列以来就开始支持DirectX 10.1,不过ATI似乎还没有从这一先进技术上获得多少实惠。

Windows Vista SP1以上系统才能提供对DirectX 10.1的支持
DirectX 10.1接口新特性
那究竟DirectX 10.1跟DirectX 10相比有什么不同呢,下面来看。如果说相对于DirectX 9来说,DirectX 10是一个重大转折;那DirectX 10.1则更多的是作为一种技术上的补充。DirectX 10.1保持了DirectX 10原有整体结构和编程模型,同时提供了许多增强功能。顶点、几何和像素着色指令集得到更新,进一步支持Shader Model 4.1,提供32bit浮点滤波改善HDR渲染画质。新功能大致上分为三类:反锯齿效能的改进,Shader及纹理能力增强,更加严密的规范等等。
DirectX 10.1主要更新内容:
1、应用程序可控制超级采样和多重采样的使用,并选择在特定场景出现的采样模板;
2、直接对压缩的纹理材质渲染;
3、支持Shader Mode 4.1;
4、更新指令支持立方体纹理贴图阵列;
5、更具弹性的资源复制和利用;
6、包括多个渲染目标的总体混合模式,以及更新的浮点混合功能。
ATI Radeon HD 3xxx和4xxx系列DirectX 10.1演示Demo

全球首款DirectX 10.1演示Demo Ping-Pong
Ping-Pong演示程序实际上是一个小游戏,在一个分成两个互联空间的密闭房子里,玩家要用1个或2个核动能电吹风把乒乓球吹到隔壁房间两侧墙壁的黑洞里,吹进的小球越多,那么得分就越高。默认的情况下,我们有3000个乒乓球要消灭,如果嫌少的话,可以通过修改程序目录中的sushi.ini文件来增加或减少乒乓球。除此以外还可以在这个文件中改变多重抗锯齿和分辨率等其它设置。

数千个各自独立物理运动模式的乒乓球互相碰撞

实时全局光照
Ping-Pong意在演示DirectX 10.1的Cube Map Arrays(立方体贴图阵列)技术所实现的实时全局光照技术,配合实时全局光照协同工作的驱动环境闭塞技术,以及空间正确反射技术和延迟渲染技术。在Demo当中数千个有各自独立物理运动模式的乒乓球互相碰撞,使用者可以使用1个或者2个吹风机,来驱动品乓球进入第二个房间,一旦乒乓球进入第二个房间,使用者可以跳跃进入第二个房间,继续使用吹风机将乒乓球吹入第二个房间左右墙壁上的吸孔来获得分数。全局光照技术,在这个Demo当中引入非常逼真的光照和阴影效果,场景当中采用区域光源提供光照,然后光照在DirectX 10.1的Cube Map Arrays(立方体贴图阵列)技术作用下,按照场景空间大小,被划分成大约200个小的立方体贴图,这些立方体贴图然后被用来进行场景物理和乒乓球本身的镜面和弥散光照处理。

全球首款DirectX 10.1演示Demo Ping-Pong
这个Demo使用到时下流行的Deferred Rendering(Shading)延迟渲染技术,也就是说立方体表面各种特质被渲染到全屏大小的数据缓冲当中,最后渲染成最终画面。延迟渲染技术,可以简化复杂场景着色渲染的复杂性,降低图形芯片的渲染透支现象。DirectX 9图形芯片也支持延迟渲染,但是无法和MSAA渲染目标协同工作,也就是说DirectX 9图形芯片无法再采用延迟渲染技术的游戏当中实现硬件MSAA。DirectX 10 API和DirectX 10硬件的出现,让这个问题得到改善,比如采用延迟渲染技术的《战争机器》在DirectX 10模式下可以完成MSAA,但是画面并非尽善尽美,还是有部分锯齿没有得到MSAA处理。

全球首款DirectX 10.1演示Demo Ping-Pong

全球首款DirectX 10.1演示Demo Ping-Pong
DirectX 10.1的出现,更让延迟渲染和MSAA不兼容的问题得到最终解决,因为DirectX 10.1可以让Shade程序访问所有数据缓冲,包括对在延迟渲染当中达成MSAA至关重要的多重采样深度缓冲。另外,DirectX 10.1的Pixel Coverage Masks(像素覆盖蒙板)或者叫做Sample Coverage Masking(采样覆盖蒙板)功能,也让DirectX 10.1图形芯片可以完成对任意纹理的反锯齿处理(包括透明纹理),因此,在采用延迟渲染技术的游戏当中,只有DirectX 10.1硬件才能提供完美的MSAA反锯齿画质。
小结:
DirectX 10的诞生,一定程度上,缓解了由于CPU负载过大而给游戏图形效能带来的尴尬局面。通过提前数据验证、纹理阵列、绘制预测、数据流输出、状态对象、常量缓冲等机制,帮助游戏的效果和效率上升到一个新的高度。而DirectX 10.1作为补充,在细节上进行了强化,效能上进行了少许优化,但毕竟是治标不治本,相对于DirectX 10没有本质的变化和提升。
事实上,微软远没有止步DirectX 10和DirectX 10.1,早前有抱琵琶半遮面的DirectX 11,现在已经悄然而至。而作为目前仅有的且唯一的DirectX 11 Class GPU,ATI Radeon HD 5870已经是弦上之箭。另外,DX11作为紧随万众期待的Windows 7操作系统一同面世的新一代DirectX API,将再次撼动当今显示卡市场的格局,因为这又将是一个新时代的开始。
下面我们将根据目前各方的信息,简单为大家介绍一下DirectX 11将为我们带来什么样的最新特性。
RV870的尚方宝剑:DirectX 11

DirectX 11
DirectX 11是Microsoft提供给性能更强的下一代GPU的最新工业标准程序接口,同时它也是已经进入RTM流程的Windows 7操作系统的重要特性之一。当然,据AMD方面透露,Microsoft也会计划为Windows Vista提供软件升级与支持。

DirectX 11
ATI此次全新推出的代号Cypress RV870核心的Radeon 5870、Radeon HD 5850和Radeon HD 5870X2是迄今为止,市面上唯一一款支持全新DrectX 11的GPU。DirectX 11最新的一项重要特性就是支持DirectCompute 11(通过全新的Compute Shader),它可以让开发者通过工具,开发出适用于并行运算性能更出色的GPU,这会比仅在CPU上运算快得多。
DirectX 11的Compute Shader,本质上就是将程序运行放在GPU上运行;这样可以使得众多的最新图形技术付诸实践:指令独立透明度、光线追踪、强化后的后期处理效果等等,这些我们将在接下来的时间里,跟大家慢慢讲解。当然,这种通用化计算也可以运用于非图形领域,例如:视频编码、超分辨率插值运算、游戏物理加速以及人工智能。
强大的并行运算能力是GPU“身兼数职”的前提

Super-Scale VLIW SIMD Micro Architecture
今天,GPU的规模使得GPU本身的性能输出已经远比付出的金钱或者功耗有价值的多。然而作为一种异构处理器,GPU缺少了一些CPU的复杂功能,同时GPU对于驱动和应用软件的依赖,这些也都对于开发者来说,是一件既行之惬意,又能挑战最大潜力的任务!以ATI RV870为代表的新一代GPU,包含的更多Direct X 11特性,使他们在拥有强大运算能力的同时,也能够变得更容易驾驭。
DirectX 11主要特征概述
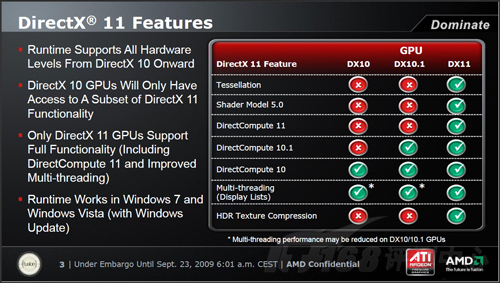
DirectX 11
从AMD此次公布的数据来看,新一代API:DirectX 11,为我们带来了全新的Tessellation(可编程式拆嵌细分曲面技术)、Shader Model 5.0、DirectCompute 11和HDR Texture Compression(HDR纹理压缩)。
上一代DirectX 10和10.1 GPUs硬件只能实现DX11的一些较底层的特效,只有硬件完整支持DirectX 11的GPU,才能够实现DirectX 11的功能和特效,包括DirectCompute 11和改进后的多线程管理等特性。但是,值得说明的是,硬件支持DirectX 10级别以上的GPU,都能够兼容DirectX 11。

DirectX 11
使用DirectCompute 11进行统一编程,需要穿越许多不同GPU架构和特性。而全新的DirectX 11程序接口解决这个问题的方案,被统称为DirectCompute Shader Model。虽然在低版本Shader Model中,也已经包含了一个超集合功能,但更高版本的DirectCompute Shader Model 5.0 包括了更多的新特性:
1、增强的并行性能
2、增强的高精度浮点数运算与整数运算
3、更紧密的结合Compute Shader与Rendering Pipeline
4、增强易编程性与显存利用效率
第五代!Shader Model 5.0详解

DirectX 11
Shader Model 5.0的主要新特性在于:
1.新的指令设置,能够更随意数据读、写、控制数据
2.Vertex Shader、Hull Shader、Domain Shader、Geometry Shader、Pixel Shader、Compute Shader 融汇贯通共享指令集。
3.以3D物体作为编程的出发点,功能和子流程的编写和执行更简便
Compute Shader相比其它同类编程模型在并行处理器方面的优势是:不论是哪种Shader类型的图形编程,它们都共享一个统一的指令集合,如Pixel Shader和Vertex Shader等等,一如上面第2条所列举Shader之种类。

DirectX 11
尽管Compute Shader是DirectX 11的“新”特性,但Shader Model还是可以通过减少部分特性集合运行于较老的硬件上。这样就允许开发者来做选择:到底是要将低版本的Shader Model运用到极致?还是选择更高版本的Shader Model来进行简化,再在老硬件上获得最大的性能?
DirectX 11提供了一种选择:这是开发者所要面对的选择,虽然这种选择可能本质目的上并无大异,殊途同归!
Shader Model 4.0 -> DirectX 10 class or newer GPUs
Shader Model 4.1 -> DirectX 10.1 class or newer GPUs
Shader Model 5.0 -> DirectX 11 class GPUs only
当然,许多有趣的算法和技术确实只有在支持Shader Model 5.0的DirectX 11 GPU上才能执行和实现。这里我们列举了Shader Model 5.0的相比Shader Model 4.0的重大改进:
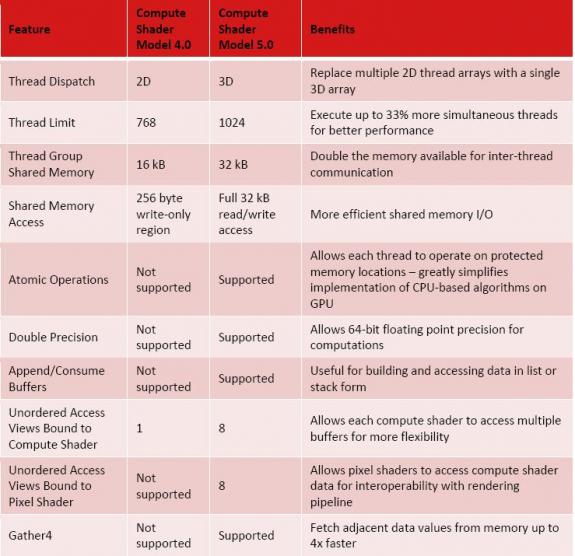
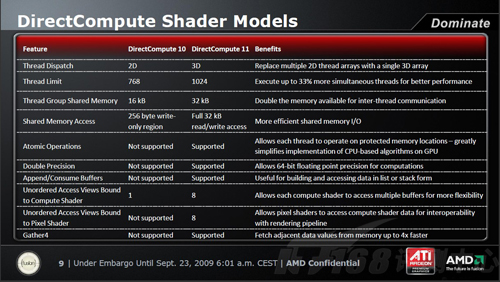
上面两幅图的实际上说的是同一个问题,只是我们或许的途径不一样。从表格中,我们可以看到,Shader Model 5.0开始支持3D线程的拆分,而Shader Model 4.0以及此前的只支持2D,同步线程数量上限也从Shader Model 4.0的768条上升到1024条,提高了33%理论上,Shader Model 5.0能够带来更好的性能表现。线程组中,线程间的互访缓存,也从Shader Model 4.0的16k上升到双倍的32k。
而片上共享的缓存的变化,Shader Model 5.0则是革新的。以往的Shader Model 4.0仅仅提供了256b只写共享缓存,而Shader Model 5.0测提了高达32k的可读可写共享缓存,效能大大提高!其它诸如:64bit精度运算(双倍精度)、Atomic Operation、Gather4以及Append\Consume Buffers,在Shader Model 5.0上都得到了支持。
Tessellation:可编程式拆嵌细分曲面技术

DirectCompute 11在游戏技术中的应用
DirectCompute 11在游戏技术中的应用,对于普通玩家,他们更关注这些新特性如何在画面品质上得以体现。
前面已经说过,DirectX 11的诞生,本质上是希望将更多的程序运行放在GPU上来实现;这样可以使得更多的最新图形技术付诸实践,比如:镜像处理和过滤、顺序无关透明、物理加速、AI人工智能、光线追踪以及强化后的后期处理(阴影渲染)效果等等。在开始讲解这些应用之前,首先让我们来看看Tessellation(可编程拆嵌式细分曲面技术)
Tessellation:可编程式拆嵌细分曲面技术

DirectCompute 11在游戏技术中的应用
事实上,最早在XBOX 360平台的图形核心Xenos上,ATI就带来了一项名为“Tessellation(可编程式拆嵌细分曲面技术)”的新技术。在后来的DX10 GPU时代,ATI推出的R6XX很热R7XX等DX10 GPUs,实际上都已经拥有这个Tessellation,只是实现方式,跟我们今天提到的DX11下的Tessellation,有少许区别。Tessellation实际上就是为了提升硬件的利用效率、用最低的资源获得最好的渲染效果而诞生的—简单点说,我们可以将它比作数据传输中的压缩技术,但是却不尽相同。

DirectCompute 11在游戏技术中的应用
我们知道,在很多有关Tessellation的原理介绍中,都这样描述:“Tessellator可以将原始的图形分成很多更小的图形,然后它还可以将这些小图形组合到一起、形成一个新的几何图形,这种几何图形更复杂,当然也更为逼真。”打个比方,Tessellator技术可以让某个图形变成立方体,并通过旋转让其从底部看起来像是个球形。而事实上,这两者使用的是相同的数据!这样就达到了节省资源的目的。
DirectX11的Tessellation处理流程

Tessellation处理流程
在DirectX 11系统中,Tessellation处理过程包括全新引入的外壳着色器(Hull Shader,简称HS)、镶嵌细分器(Tessellator)和域着色器(Domain Shader)三个组件。其中HS外壳着色器负责接收琐碎的图形数据和资料,镶嵌细分器(Tessellator)只负责分块处理,它根据HS的指令要求生成大批量的、确定数量的点,然后将数据传送给域着色器(Domain Shader),再由它来将这些点转换成3D处理中的顶点,最终就生成了相应的曲线和多边形。
下面请看AMD此前做的一次Demo演示:硬件可编程式拆嵌细分曲面技术(Tessellation) via 三种不同的渲染模式。

第一种是最传统的凹凸贴图(Bump Mapping)
第一种是最传统的凹凸贴图(Bump Mapping),又称为皱面贴图。Bump Mapping在每个待渲染的像素在计算光照之前都要加上一个从高度图中找到的扰动,得到的结果表面表现更加丰富、细致,更接近物体在自然界中真正的模样。在2560×1600分辨率下使用AMD Radeon HD 5870显卡上以Direct3D 11 API渲染(下同),帧率494FPS。

第二种是视差贴图(Parallax Occlusion Mapping)
第二种是视差贴图(Parallax Occlusion Mapping),又称位移贴图(Offset Mapping)或者虚拟位移映射(Virtual Displacement Mapping),是凹凸贴图技术的改进和增强版本,现场渲染帧率72FPS。

最后也是最真实、自然的就是DX11中引入的拆嵌细分曲面(Detailed Tessellation/Tilling)
最后也是最真实、自然的就是DX11中引入的拆嵌细分曲面(Detailed Tessellation/Tilling)了。这种技术简单地说就是使用线框填充平面,且没有重叠和空隙,平面的外表面不会再显得方方正正,最后渲染出来的物体表面也会具有更丰富、更真实的细节。从之前AMD的演示Demo来看,Radeon HD 5870渲染帧率达到了173FPS,对比视差贴图效果和性能都更好。
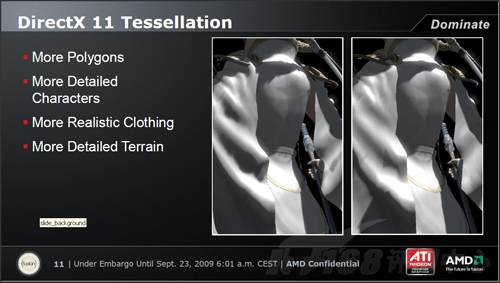
Tessellation技术能够极大程度提升游戏性能
总言之, 如果开发者能够娴熟地运用Tessellation技术,那么就能够极大程度提升游戏性能,或者说在保有当前性能的条件下显著提升画面品质。微软之所以在DirectX 11中纳入这项技术,很大原因就是因为Tessellation确实具有显著的效果,以至于微软无法拒绝。
DirectCompute 11在游戏技术中的应用
前面已经说过,DirectX 11的诞生,本质上是希望将更多的程序运行放在GPU上来实现;这样可以使得更多的最新图形技术付诸实践,比如:镜像处理和过滤、顺序无关透明、物理加速、AI人工智能、光线追踪以及强化后的后期处理(阴影渲染)效果等等。 这里着重讲一下几个重点。

指令独立透明(OIT,Order Independent Transparency)
指令独立透明(OIT,Order Independent Transparency),也有做顺序无关透明(OIT,Order-independent Transparent)翻译的,二者稍有出入,后者的解释更贴近实际,不过这个不重要,因为二者的最终目的都是Transparency(透明),这里就不深究。应该说,透过OIT,今后3D场景中的火焰、烟雾、毛发、草皮、水面、栅栏、树叶等等透明、半透明、重叠物等等的渲染将更加贴近实际。
下面是两组图,分别开启和关闭OIT。请点击放大!


事实证明,在表现既透明又重叠的多重透明场景时,开启OIT后的渲染效果明显更加真实,更加正确!
强化后的后期处理

跟之前一样,经过强化后的后期渲染能够获得更加真实的领域深度、动态模糊、平滑效果、锐利效果、边缘探测等等。
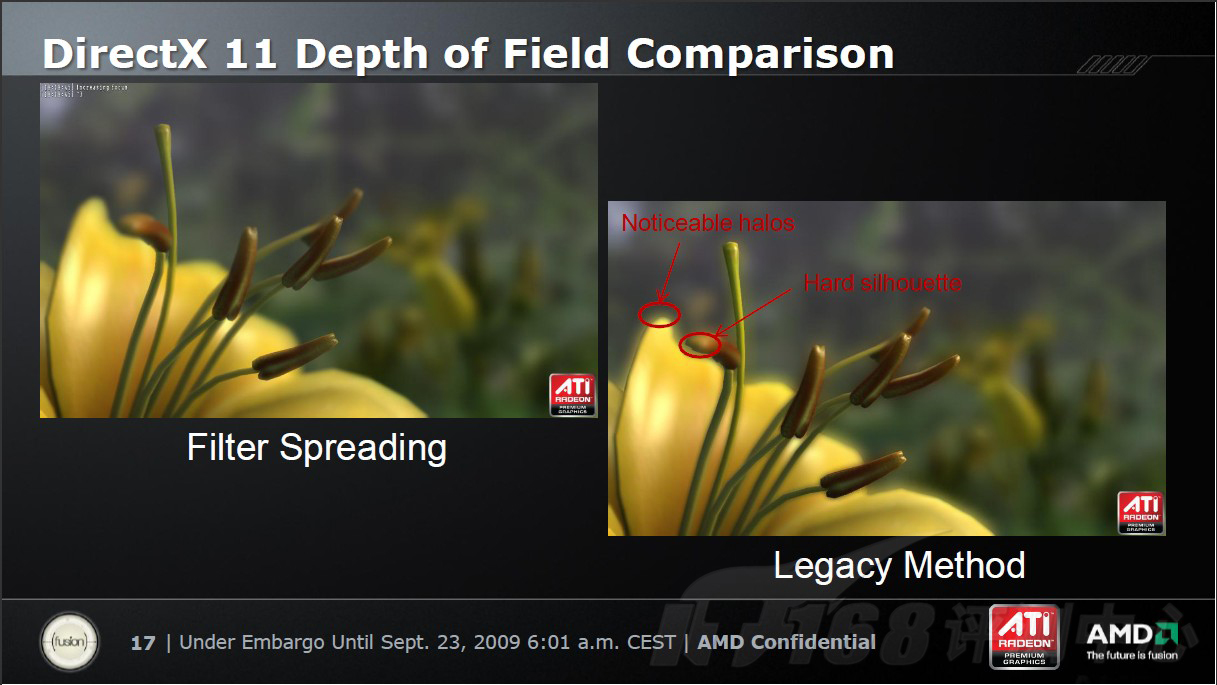
High Definition Ambient Occlusion,简称HDAO,翻译为高清晰环境光遮蔽,用于提高阴影质量。

HDAO高清晰环境光遮蔽。这是一种基于纹理的阴影技术,能提供比普通环境光遮蔽更好的效果,同时保证系统性能足够好。


DirectX 11的Texture Compression(纹理压缩)支持16bit HDR压缩,比例最高6:1。
DirectX 11:更多的并行线程处理
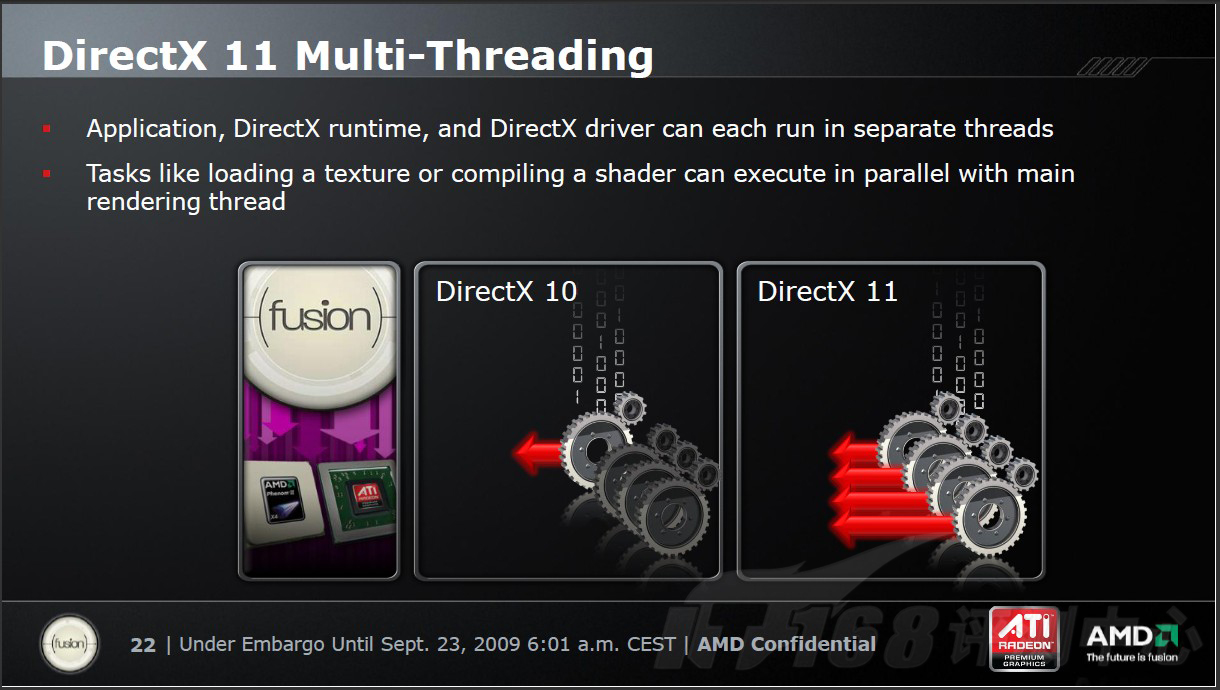
DirectX 11能够提供更多的并行线程处理能力。
DirectX 11带来了更加宽松的编程环境。
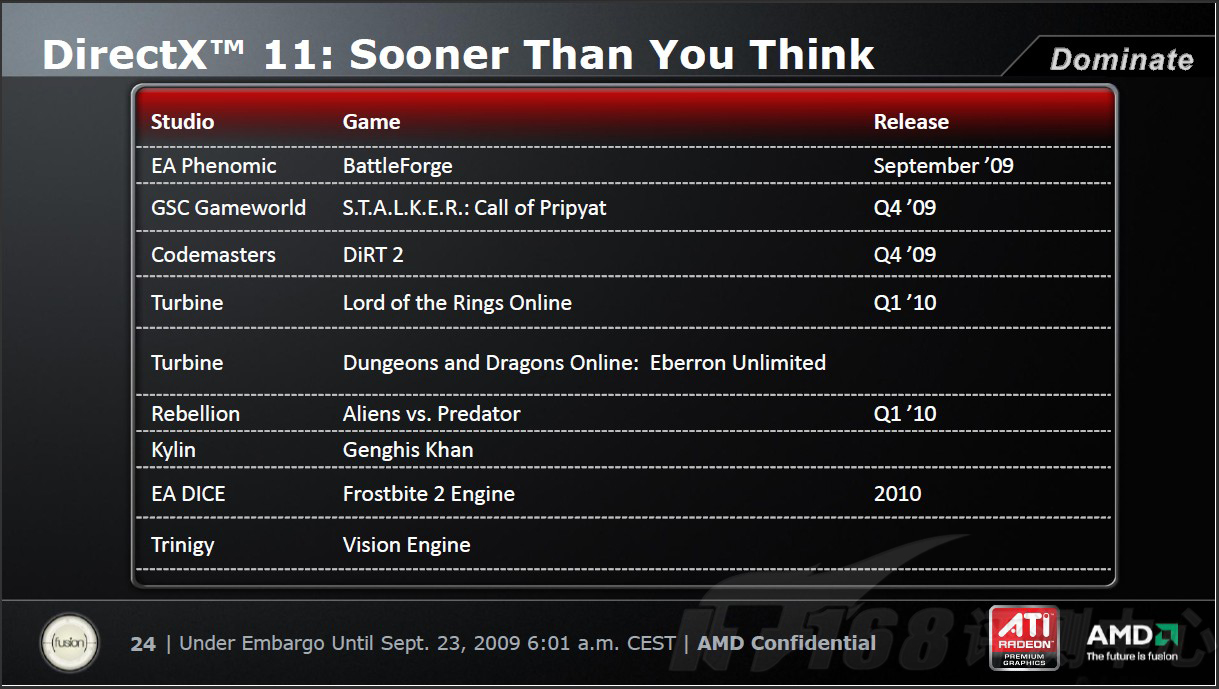

AMD用了一句“Sooner Than You Think”来形容支持DirectX 11的游戏。我们相信,在微软和AMD的共同推动下,未来会有越来越多的DX11游戏发布上市,而且,这个过程会比想象中的来的快的多!
视觉无极限:ATI Eyefinity技术

除了DX11的光环,超强的性能和相当不错的功耗表现,此次AMD-ATI Radeon HD 5870还为我们带来了ATI的全新多显示技术:Eyefinity!
AMD表示,ATI的整个DX11显卡产品线都会支持Eyefinity技术,不过非Eyefinity特别版或者低端型号最多只能连接三台显示器。该技术的实现得益于新的DisplayPort接口:AMD在DX11 GPU内集成了六条DisplayPort输出信道,每条信道连接一台显示器,全部由一个显示引擎驱动。
软件方面支持Windows Vista/7和Linux操作系统,而且如果在催化剂控制中心里开启SLS模式(Single Large Surface),六台独立显示器就会被视作是单独一台拥有超高分辨率的显示器,现在经常碰到的多显输出麻烦完全不存在了。
多显系统不仅对显卡有特殊要求,显示器同样重要。为此,AMD目前正在和业内显示器巨头洽谈,筹划合作将推出专为ATI Eyefinity技术设计的新显示器。这些显示器的两大特点就是:一是配备DisplayPort接口,二就是边框非常窄,以尽量消除多台显示器并排带来的“分割线”,带来“无缝沉浸”的视觉体验。

Radeon HD 5000系列单个GPU就能同时连接最多六台液晶显示器,每台分辨率最高2560×1600(30寸),按照3×2的方式排列总分辨率就是7680×3200,亦即2457.6万个像素。而事实上,人眼只能直接处理大约700万个像素。
显示器的数量和排列方式是灵活的,除了六台3×2还可以五台5×1横向组合也可以3台3X1横竖随意。
下面,是几种显示器的摆放方式。

三横
三竖
1竖2横
竖横竖

3×2横

3×2横
运用ATI Eyefinity技术,即使是使用22寸液晶(1680×1050)也能获得8400×1050的超宽分辨率,打游戏看电影,来将会有无比宽阔的视野。
透过RV870看今天的ATI Stream

关于RV870以后,ATI Stream的应用问题,会主要围绕Direct Compute 11和Open CL来进行。而关于这方面的内容,我们会在后面的专门撰写一篇相关文章,解读ATI Stream最新的发展趋势。





Open Physics

与NV和Intel分道扬镳,分别收购PhysX和Havok不同,ATI一直没有明确自己的物理加速方案。最近,NVIDIA已经明确在190.xx后最新驱动中,禁止ATIGPU存在时使用Physx加速。而此传出的消息,又让我们不得不另眼看待转投Pixelux and Bullet下Open Physics的ATI。
关于这一点,限于时间和篇幅的限制,我们会在后面专门为大家撰写一篇相关的文章,解除大家心中的疑惑。而今天在此,我们仅仅将这个问题提出来,抛砖引玉,后面再为大家做详细的解读。
加强版的UVD2.0:双1080P视频流
相信大家对在Radeon HD 2000/3000系列上大受好评的AMD高清视频解码技术UVD(Unified Video Decoder)都非常了解了,而采用RV770显示核心的AMD Radeon HD 4870在去年为我们带来了新的UVD2.0。UVD2.0在传承了第一代UVD技术的优良设计的同时,还进一步对其进行优化。

AMD的UVD技术可以说是将CPU解放出来,可以对H.264和VC-1进行完美的硬件解码。而第二代UVD技术在高码流的播放上进行了优化,甚至可以播放码流超越40Mbps的片源。另外还可以对超高分辨率视频解码,新一代的UVD技术甚至可以对高达2160P分辨率的片源进行解码。而且更让大家吃惊的是,第二代UVD技术还加入了多流解码,即同时解码多部高清影片,这要比双流解码更强大。

在RV870上,ATI带来了改进型的UVD2.0。硬件支持双1080P视频流加速,这一点还是非常吸引人的。UVD在各方面的升级,能为大家带来更加出色的高清体验,同时也不用考虑在解码过程中CPU的承受能力。
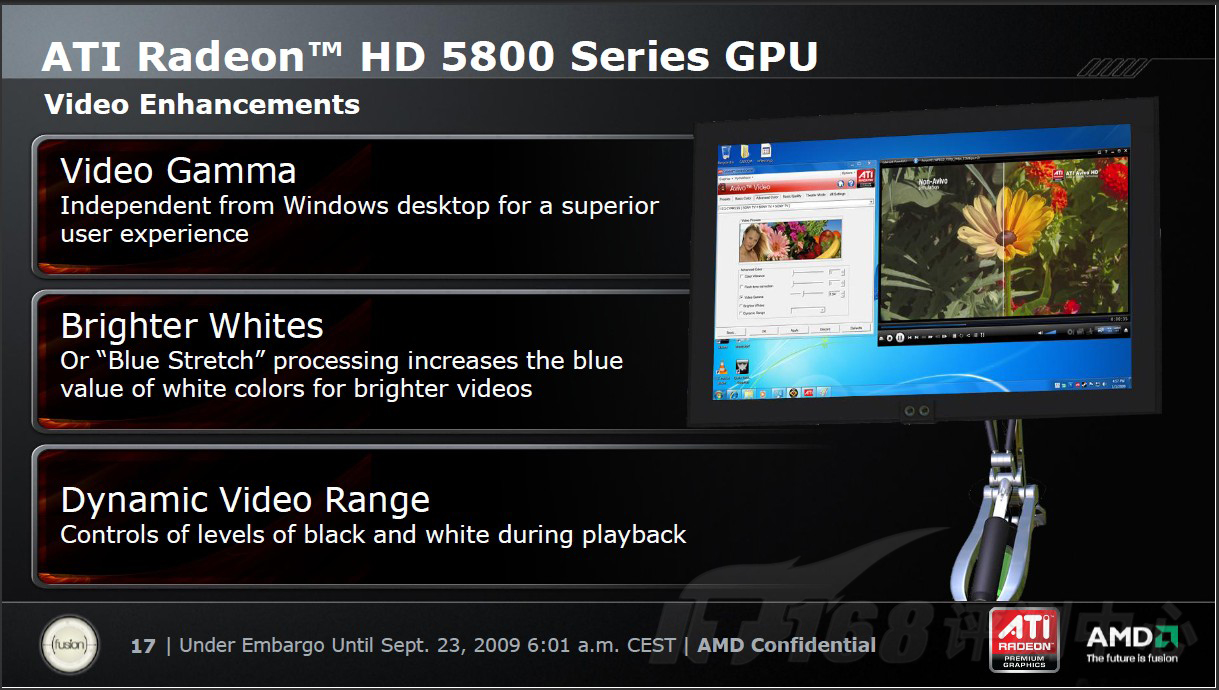
RV870的Radeon HD 5870在视觉设置上有着诸多改善,诸如更宽松的Gamma调节,“蓝色延展”技术,黑白延伸技术等等,都为提供更好的视觉输出质量提供了有力的保证。

HDMI 音频改进:支持HDMI 1.3a,通过Dolby TrueHD和DTS-HD Master Audio认证;完整支持所有蓝光音频格式;支持7.1声道192kHz/24-bit声音回放。

HDMI 视频改进:支持HDMI 1.3a Deep Color和x.v. Color;HDMI输出色彩能力达到10亿色;支持广色域!
Win 7+全新Catalyst = 20%效能提升

即将正式发布的Windows 7不光给我们带来了DirectX 11,还提高了系统整体的运算效能。从上面的图表中,我们已经能够充分的感受到,ATI多年在驱动方面下的功夫!
这一次,ATI再次信心满满向世人宣布:ATI个产品线的Windows 7 WHQL驱动已经准备完毕,而且,效能相比Vista下有显著的提高!
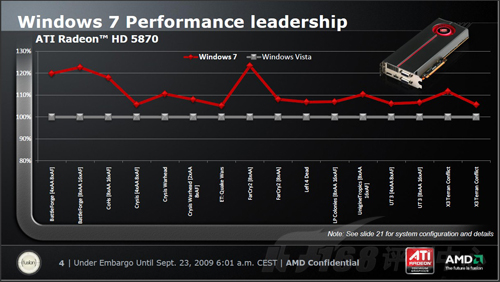
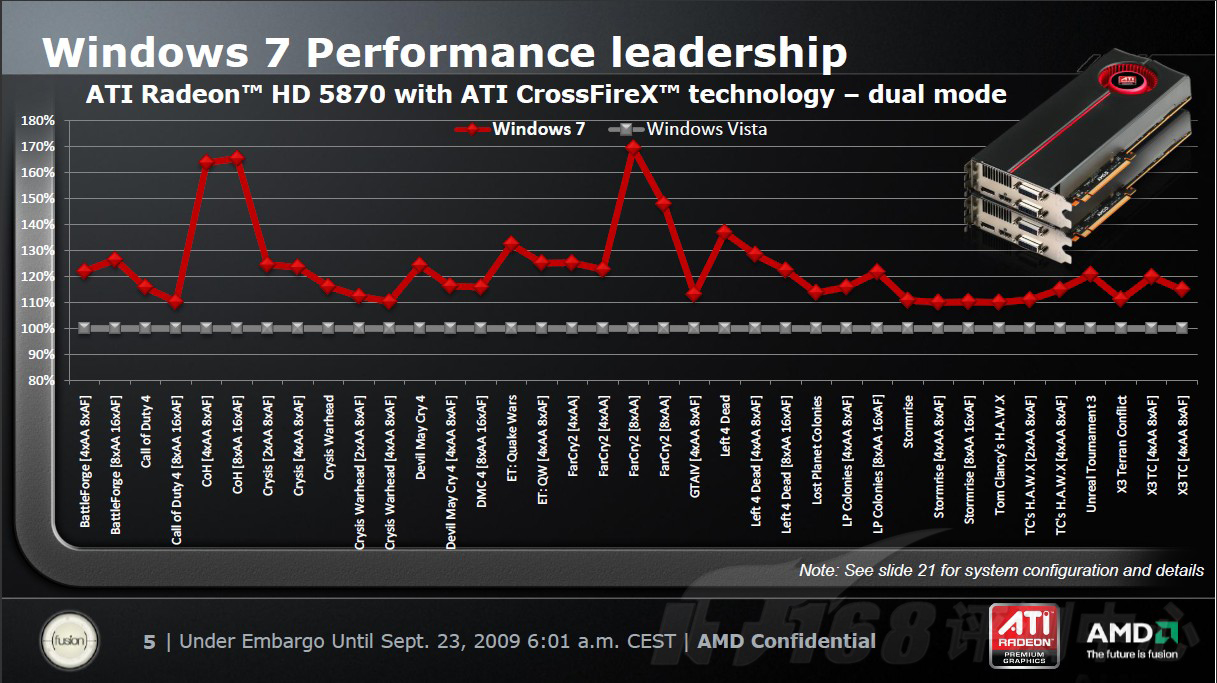
根据ATI的研究资料显示,在Windows 7下,Radeon HD 5870单卡效能最高能够提升20%,而双卡情况下,提升幅度最高可达70%!可见,对于全新的Radeon HD 5870以及即将上市的一系列Radeon HD 5xxx系列,Windows 7和改进的Catalyst驱动,是他们理想的搭配选择。
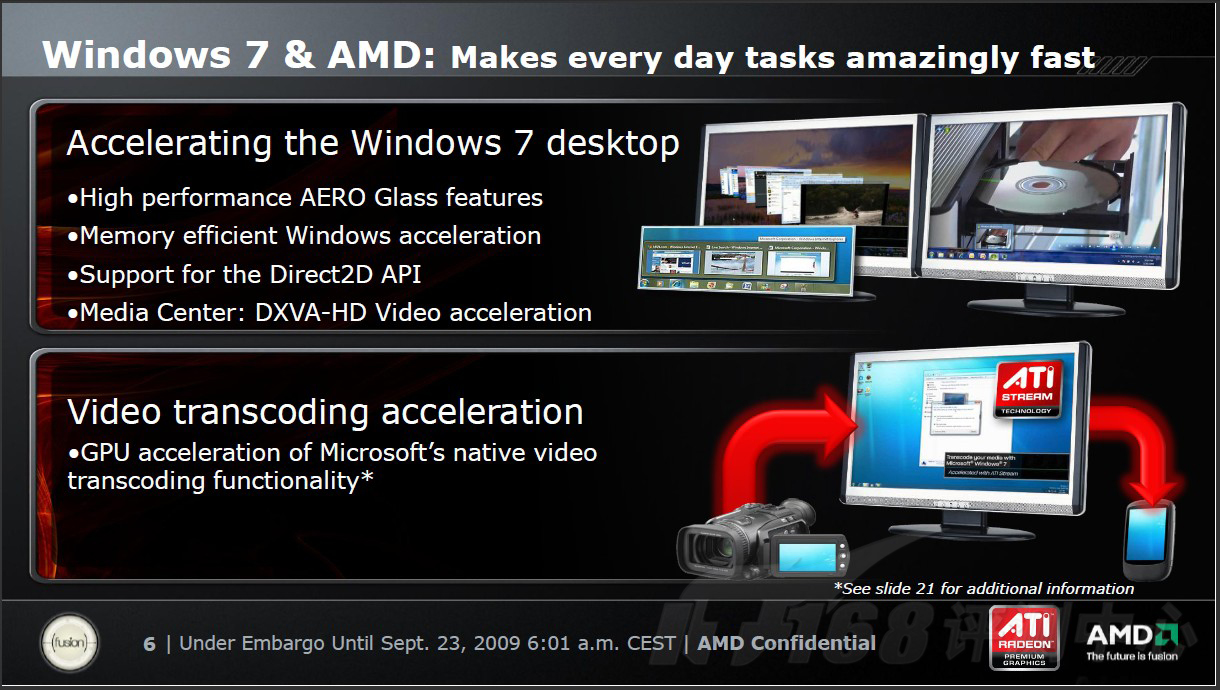
除了3D应用,在其它方面,ATI的Catalyst显示驱动,也已经和Windows 7配合的相当完备!
ATI的Sweet Spot策略——

设计芯片技术不是唯一,设计策略才是大局转变的关键
经过R600的失败和RV670的启发后,ATI开始在产品开发思路上走着和NVIDIA不一样的路:由于在早期人类并设有预见到当集成度与微观世界发生联系定律会遇到如此多的问题,大量的物理化学定律在微观领域中失效或被改写,半导体的发展不再只局限于制造工艺,转而材料学开始成为晶片设计制造水平和可靠性的关键问题,同时成为芯片性能提升的重要因素。所以ATI认为NVIDIA那种通过盲目增加核心面积,塞进更多的晶体管去提高芯片性能的方案已经寸步难行。

GT200夸张的核心面积
从GT200身上我们可以体验到NVIDIA那种为求提升性能而继续不择手段的疯狂,不过AMD/ATI他们却不希望GPU继续走着这样的老路子:先造出一颗大型GPU,然后不断屏蔽一部分规格以对应不同市场。基于产能和可扩展性的考虑,ATI开始把每一代核心的开发重点放在中型级芯片上,然后采用单卡双芯的方式推出优异显卡。

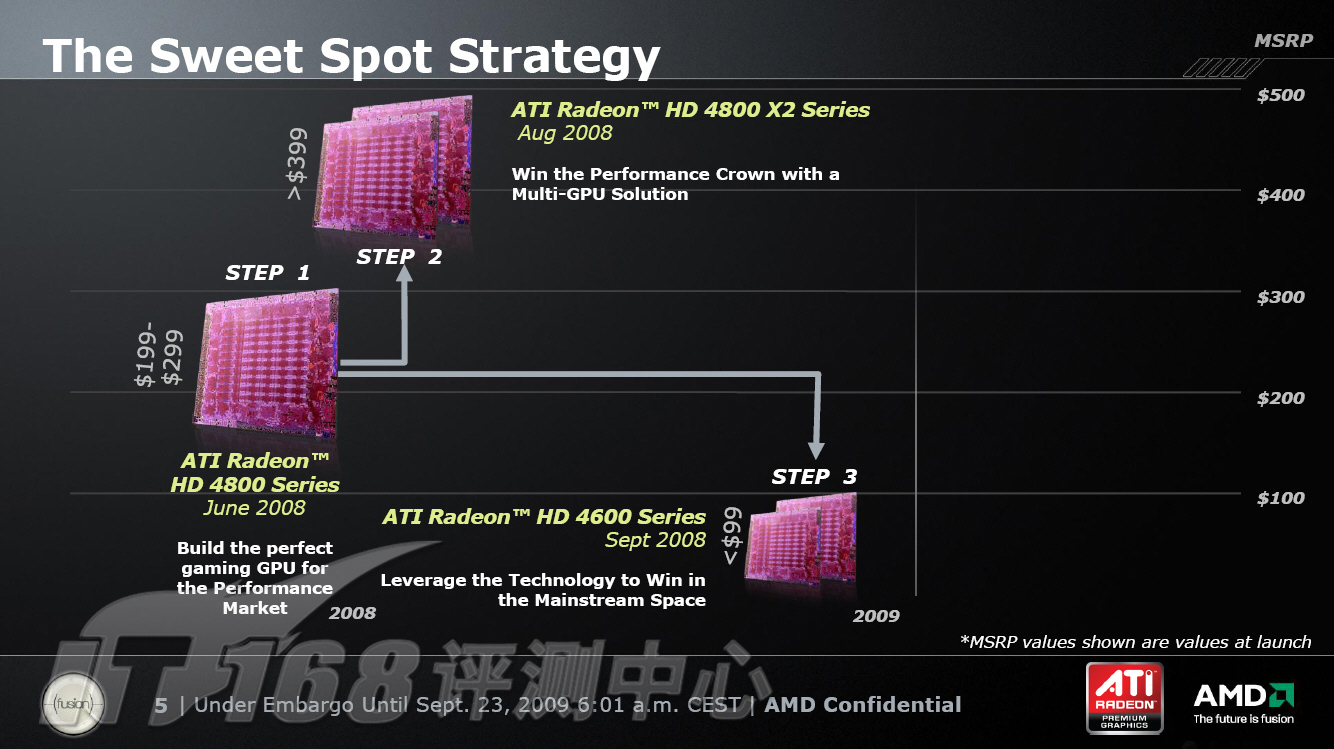
Sweet Spot策略正式起源于RV770时代
在2005年的时候,ATI和NVIDIA都面临这样的情况:造一颗最快的GPU,并提供稳定的驱动程序,那么就可以赢得市场,在DirectX9时代乃至DirectX10初期ATI一直是这么做。但是在ATI内部有一些人认为是时代改变了,在很多方面ATI和NVIDIA都面临不同的挑战,NVIDIA从之前激进的工艺更新策略中汲取了教训,GT200仍然采用老的,更成熟的工艺,因此导致GT200的面积很大。ATI选择走一条NVIDIA没有走过的路,在制造工艺问题日渐严峻的情况下选择制造更小面积的GPU——2005年当时草拟的结论正是2008年大有成就的RV770系列。

RV870时代的Sweet Spot策略延伸
经过RV770的初步成功经验,ATI对RV870就更有信心了,RadeonHD5800系列仍然遵从Sweet Spot策略,采用中型单核产品作为性能级的代表,通过双核形式来与对手较高级单核产品进行对抗,同时对性能级中型核心作一定程度简化,衍生出主流级的其他产品。Sweet Spot策略显然还为ATI争取了最宝贵的时间,因为设计和生产中型核心的难度和周期远低于大型核心,所以这次RV870的发布速度要比GT300发布早不少。
RV870架构解析:Radeon HD 5870的绝密武器
ATI的设计目标

RV870的设计目标其实一开始就很明确:
1、完整硬件支持DX11,而且ATI给自己下的目标是在DX11 API发布之前,完成支持DX11的RV870软、硬件设计设置。这种严要求让笔者不禁想起来当年R300核心的Radeon 9700发布的时候,也是同样的情况。在Radeon 9700上市的时候,微软的DirectX 9还未正式露面发布。而今天的情况也很类似。
2、飙升RV870在DX9和DX10中的性能表现,特别是在高分率下的表现。
3、构建硬件支持OpenCL 1.0和DirectCompute 11的通用计算平台。
4、在功耗相当的情况下,旨在提供2倍的运算处理能力
5、创新点:ATI Eyefinity等
我们可以看到,在如此严格而缜密的要求下,RV870的设计研发有着非常明确的目标。因此,从另一方面讲,我们今天看到的RV870,承载着ATI无数工程师的梦想和希望!那么,RV870到底在架构细节上又怎样翻天覆地的变化呢?
RV870架构概述及横纵对比
RV870的核心架构被称为“TeraScale 2”,处理能力相比上代RV770翻了一番甚至还多,并有多处增强:指令集、流处理单元、SIMD布局、图形引擎、纹理单元、渲染后端、显示控制器等等。

Radeon HD 5870(RV870)架构:20组SIMD阵列,每组SIMD包括16个Shader,每个Shader包括5个流处理器RV770总流处理单元(Stream Processing Units)数量就是:20×16×5=1600个!是RV770的整整两倍!

特别值得一提的是,为了容纳这1600个流处理器单元,ATI的设计师将它们分成了两部分,左右两个SIMD阵列群,拥有各自的Interpolator、Setup Engine、Texture Units、L1 Texture Cache和Local Data Shares,相互之间全局共享数据,并一起通过CrossBar连接L1和L2,以及输出前端到RBE。
ATI此次放出这样的架构图,很容易被认为RV870是“双核心”,其实只不过是为了方便布局而做的更改。

Radeon HD 4870(RV770)架构图
上一代Radeon HD 4870(RV770)架构:10组SIMD阵列,每组SIMD包括16个Shader,每个Shader包括5个流处理器RV770总流处理单元(Stream Processing Units)数量就是:10×16×5=800个。
图形前端引擎
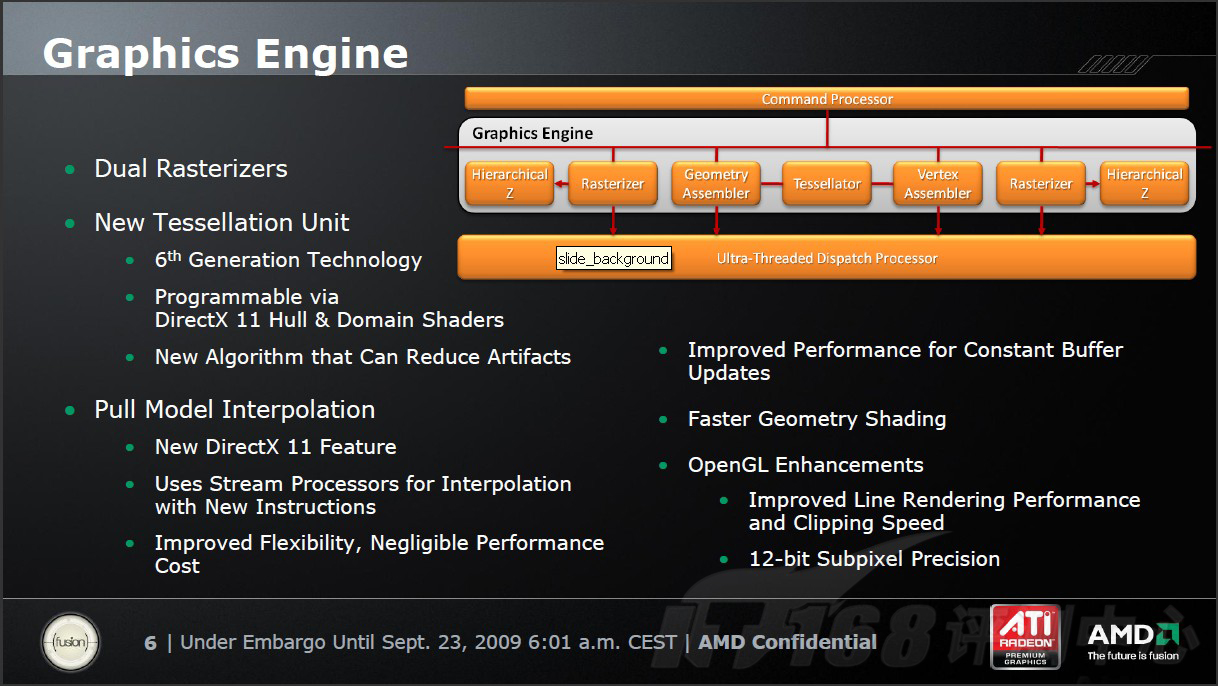
RV870上的这个Graphics Engine实际上就是RV7xx和RV6xx身上的Setup Engine的升级加强版。它由两个光栅化单元(Rasterizer),两个递阶Z(Hierarchical Z)、一个顶点装备器(Vertex Assembler)、一个集合装配器(Geometry Assembler)和一个拆嵌细分器(Tessellator)组成。
较之以前,区别比较大的就是这个Tessellation。全新的Tessellation已经是ATI产品线中的第六代Tessellation,支持DX11的同时,在效能上相对之前的版本也有相当的提高。关于Tessellation的有关详情,请参考我们前面在DX11简介中提到的相关内容。
线程处理器

在SIMD陈列规模扩大的同时,Ultra-Threaded Dispatch Processor(超线程分配处理器)也变得更加复杂。由于每组SIMD所包括的Shader数量增多,阵列内的Arbiter(仲裁器)和Sequencer(定序器)数量同比增加,目的就是为了确保扩充规模后,RV870单个Shader执行效率不会下降。
80个问题单元(Texture Units)

我们知道,R600/RV670/RV770的纹理单元内部结构实际上是相同的,但是2008年推出的RV770,其TMU的数量相比/R600RV670就已经翻了2.5倍,从4组增加至10组,这样,RV770总共就是40个纹理单元,Shader和TMU的比例达到了4:1。而RV870的SIMD阵列又从RV770的10组激增到20组,那么相应的,RV870总共就是80个纹理单元,SIMD Shader和TMU的比例仍为4:1。
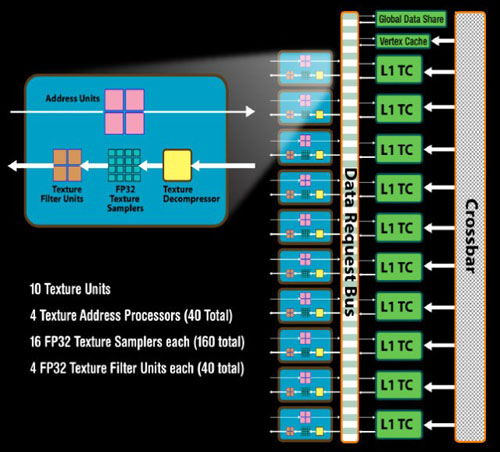
RV770
关于RV870问题单元部分的细节,AMD暂时没有给出明确数据,以下的数据,参考RV770得到:每组纹理单元内部包含了4个纹理寻址单元(粉红色,共80个),16个32位浮点纹理采样单元(浅蓝色,共320个),4个纹理过滤单元(橙色,共80个),1个纹理解压单元(黄色,共20个)。
再来看看细节部分,可以看到8个黄色的纹理寻址单元和20个FP32纹理采样单元还要区分大小,这是因为顶点着色只能使用到其中4个小纹理寻址单元进行纹理采样,而像素/几何着色则可以使用全部的8个;顶点着色只能使用其中4个小FP32纹理采样单元,而像素/几何着色则可以使用全部的20个。
全新的纹理过滤算法

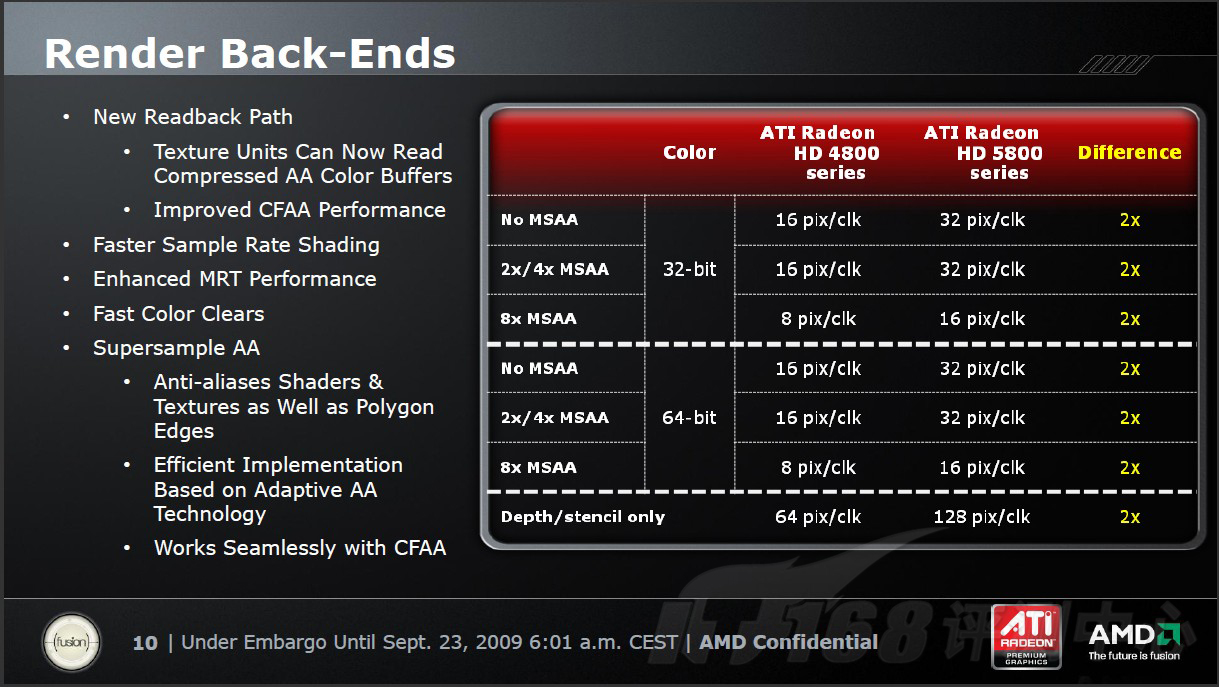
AMD的RBE(Render Back-Ends)等同于NVIDIA的ROP,都是负责光栅化像素输出及抗锯齿等后期处理任务,也是4×4架构,因此通常认为R600/RV670和G92一样包括16个ROPs。RV870的每个ROP可以在一个时钟周期内采样32个Z/模版,而且深度/模版是分开处理的,执行效率更高。从上一代RV770几乎免费提供2xMSAA来看,在RV870上实现真正的Free 4xMSAA甚至8xMSAA也不是不可能。这一点,将在我们后面的测试部分为大家解答。
下面,是AMD提供的一张4xMSAA和8xMSAA性能损失比较表。
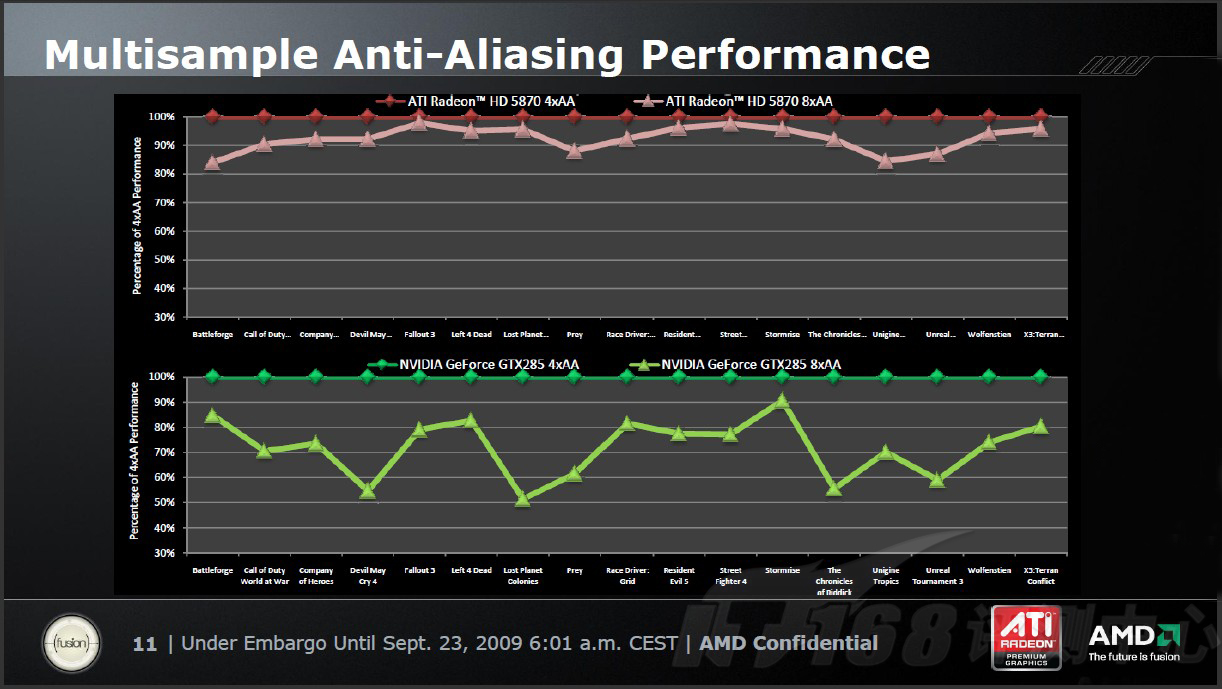
从图中可以很明显的看出,相比nVIDIA目前最强单核显卡GeForce GTX 285,基于RV870核心的Radeon HD 5870,从4xMSAA提高到8xMASS时,性能损失仅仅为1%-20%。相同情况下,GeForce GTX 285的性能损失达到了10%-50%。因此,可以明确的是,在高分辨率高画质高倍AAS情况下,RV870有着比GT200好得多的性能表现。对于骨灰级玩家来说,无需置疑的是,现阶段ATI提供了更优的决绝方案。
显存控制界面
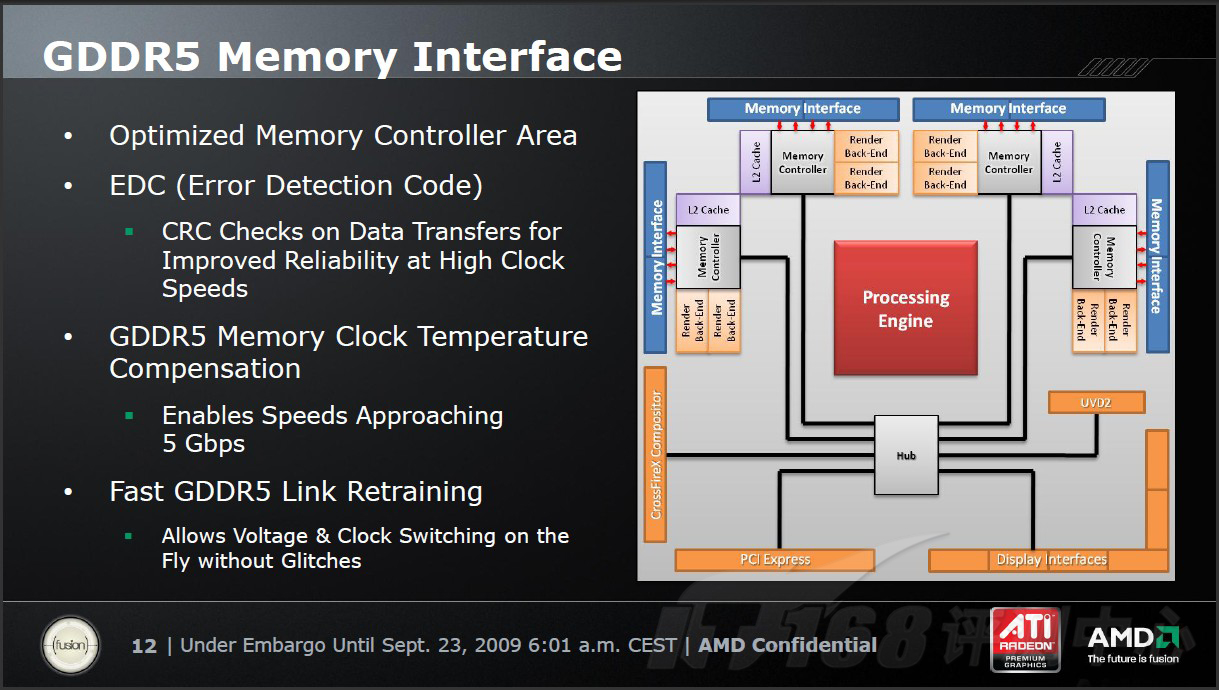
同RV770的4870和RV790的4890一样,RV870的Radeon HD 5870采用了GDDR5的显存界面,同时AMD还对显存控制器区域进行了细微的优化和调整。值得一提的是,AMD此次强调Radeon HD 5870采用的GDDR5是第二代,原因在于它支持错误校正代码,能够在数据传输的时候进行CRC校验,提高了GDDR5显存的哦高频稳定性和准确性。
关于目前ATI产品的显存控制器到底是RingBus还是CrossBar的问题,笔者想在这里强调一下:不管RingBus,还是CrossBar,他们的最终目的都是为了合理控制显存和核心的数据交换,力求最短路径、最低延迟、最高效率。因此,不管是RingBus还是CrossBar都只是一种实现形式,它们各有优劣。目前GPU的发展,显存控制器形式带来的性能影响,远没有显存位宽来得直接、明显。简言之,笔者想说的是,2005年X1800XT上诞生的RingBus,放在今天看也已经是相当“老成”的技术了,没有什么技术壁垒。AMd方面没有详细公布数,我们也不必就此问题深究。因为,它们的形式到底是什么,已经不重要了。
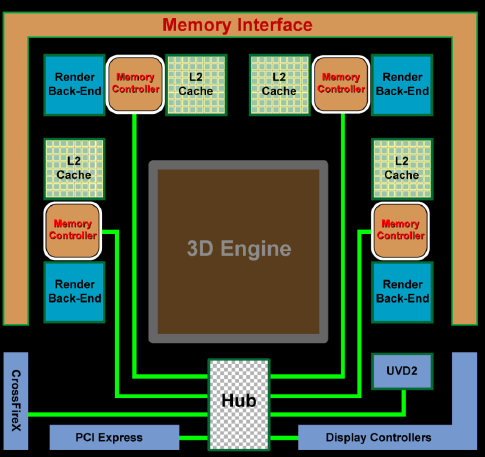
可以看到,与RV770的这部分相比,RV870并没有什么本质的变化,只是上端的RBE和L2 Cache位置有所微调,相互调换,其它部分基本相同。
AMD-ATI的“流计算”
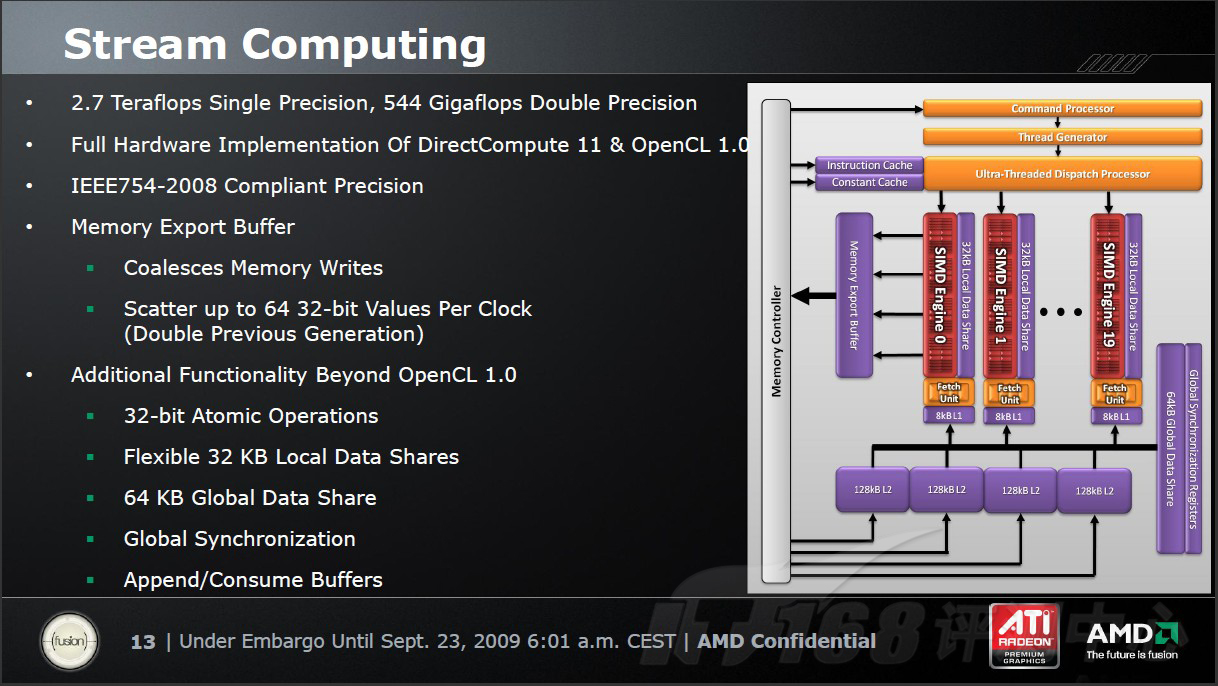
AMD-ATI Radeon HD 5870的浮点计算能力达到了惊人的单精度2.7TFlops、双精度544GFlops,这个速度几乎是NVIDIA Tesla C1060(GT200架构)的七倍之多。同时,RV870还提高了每时钟循环的指令数(IPC)。
Radeon HD 5870/5850规格参数
Radeon HD 5870/5850的核心研发代号均为Cypress。它延续了AMD近年来的“Sweet Spot”策略,即不再一味追求庞大核心、极限性能,而是从主流市场着手,设计出一个面积不大但性能足以令人满意的小核心,然后在此基础上向两个方向发展:向上采用单卡双芯挑战更高性能,向下则继续精简核心以满足中低端用户。
代号Cyress的RV870 Radeon HD 5870/5850再往上就是代号Hemlock Radeon HD 5870 X2(预计R800),预计十月底推出;向下首先是Juniper Radeon HD 5770/5750(RV840),也会在十月底发布;然后还有更小的Redwood(RV830)和Cedar(RV810),不过要等到明年第一季度才会面市。


Radeon HD 5870/5850的具体规格参数
- 制造工艺:40nm
- 晶体管数量:21.5亿个
- 核心面积:约为338平方毫米
- 流处理器:1600/1440个
- 纹理单元:80/72个
- 光栅化单元:32个
- 核心频率:850/725MHz
- 浮点性能:2.72/2.09TFlops(单精度)
- 显存位宽:256-bit
- 显存类型:GDDR5
- 显存频率:1200/1000MHz(等效4.8/4.0GHz)
- 显存带宽:153.6/128.0GBps
- 待机功耗:27W
- 满载功耗:188/170W
- 最大分辨率:3×2560×1600(六屏输出需Eyefinity特别版)
- API支持:DirectX 11、Shader Model 5.0、OpenGL 3.2
- 通用计算:DirectCompute 11、OpenCL 1.0


相比RV770的Radeon HD 4870,RV870的Radeon HD 5870核心面积增加了仅仅27%,而晶体管的总数却是原来的225%,达到了21.5亿,显存带宽也同样增加了33%左右。
动态电源管理

特别值得一提的是,在晶体管翻2.25倍,核心面积增大的情况下,5870的满载功耗仅仅增加了17%,即28W,达到188W,而待机功耗则从原来的90W,下降到27W。这样的功耗表现不得不说是一个让人异常惊喜和满意的结果!
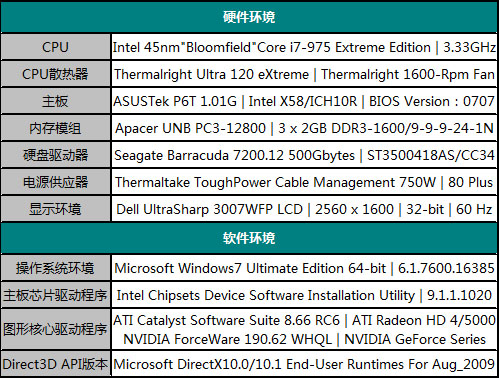
关于我们的测试
我们尽可能多的打开游戏中的画质设定并将其开到最高;我们尽可能的使用游戏里的反锯齿(AA)和各项异性过滤(AF)设置并分别将其设定4倍和16倍,只有当游戏本身没有提供反锯齿(AA)设置时才会在驱动程序中开启,而驱动程序中的垂直同步(Vertical Sync)选项始终是被我们关闭的;除了强制关闭垂直同步(Vertical Sync)的相关命令和参数,我们并不会对游戏的任何配置文件进行修改,因为绝大部分的用户都是不会这样做的;我们的每一组游戏帧数均是通过运行三次之后取平均而值得出的。

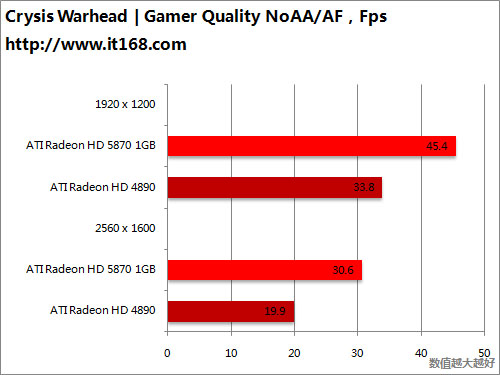
HD5870 v.s. HD4890
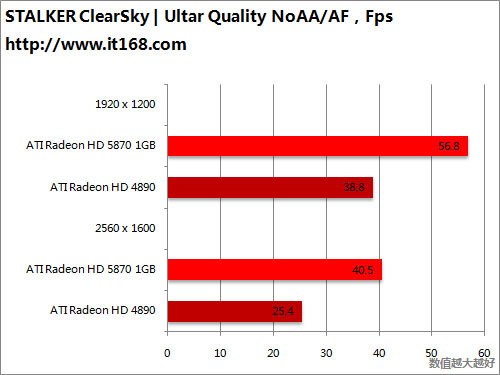

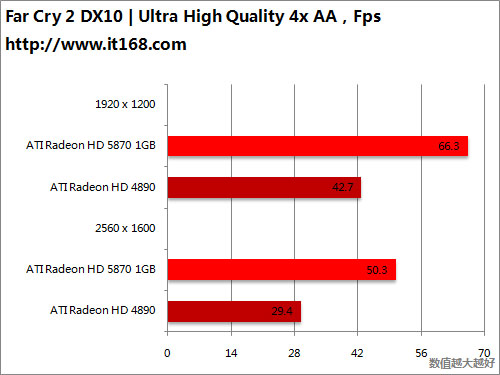
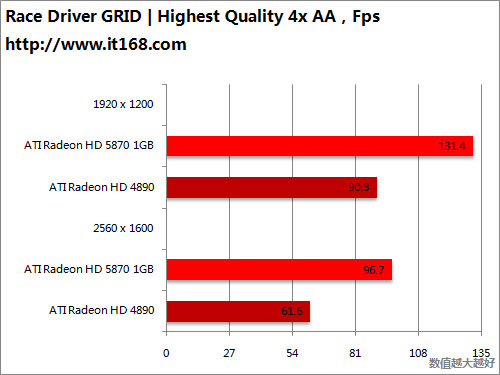
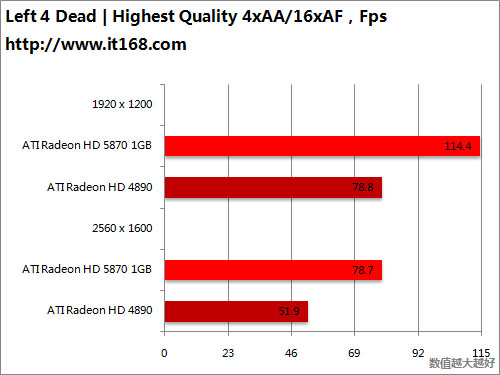
HD5870 v.s. HD4870 X2
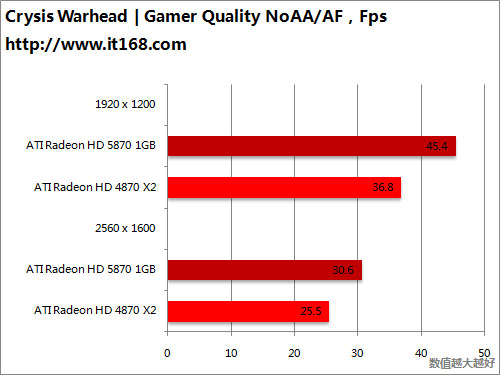
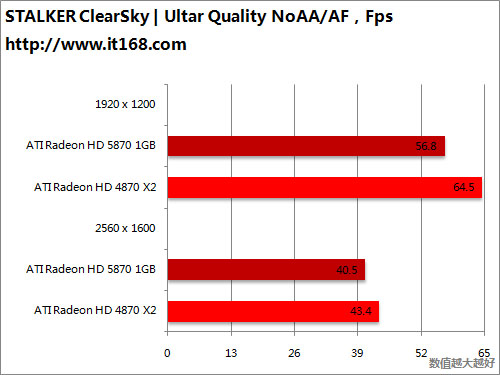
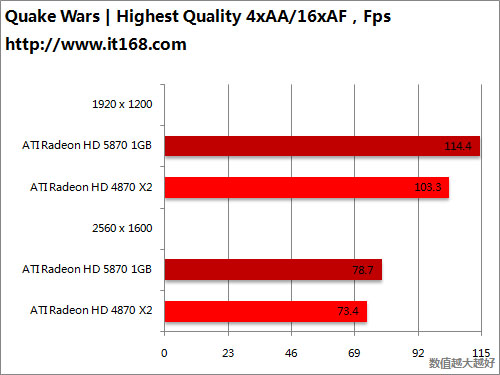
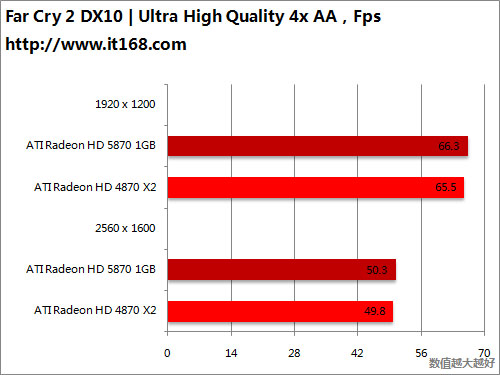
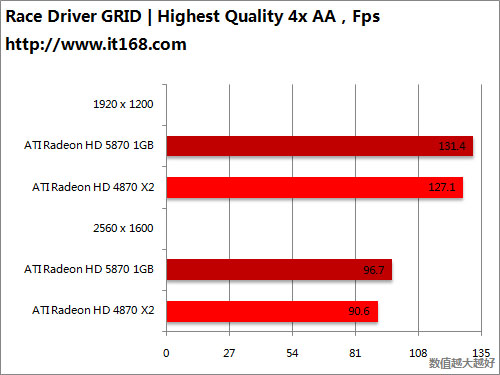
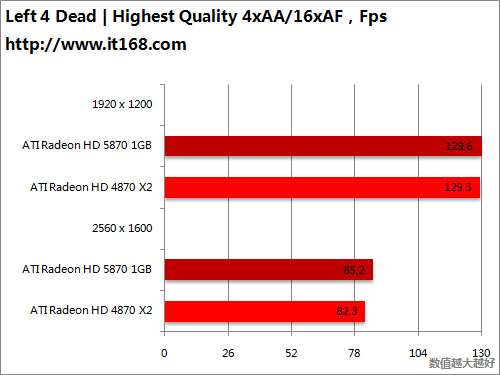
HD5870 v.s. HD5870 CF
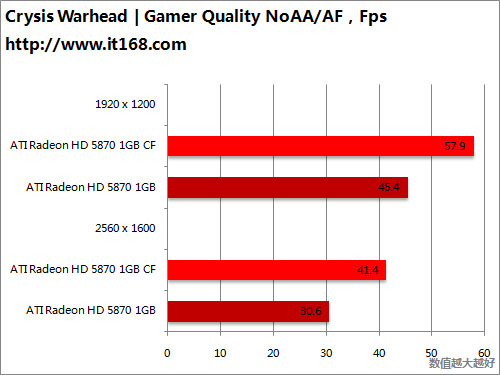
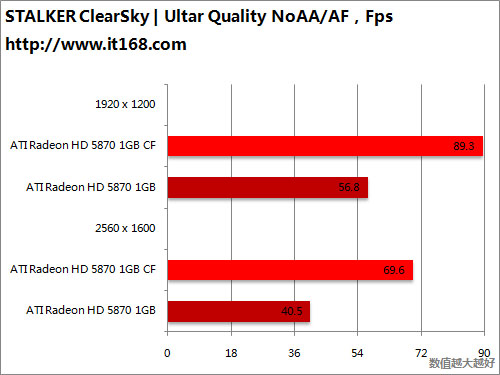

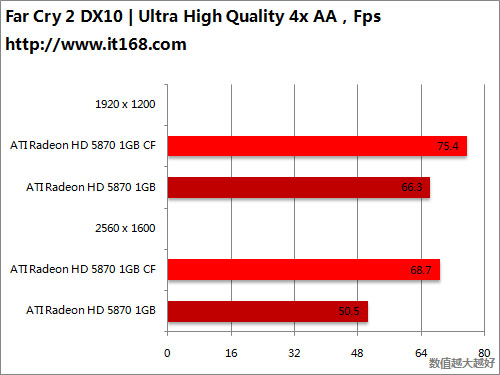
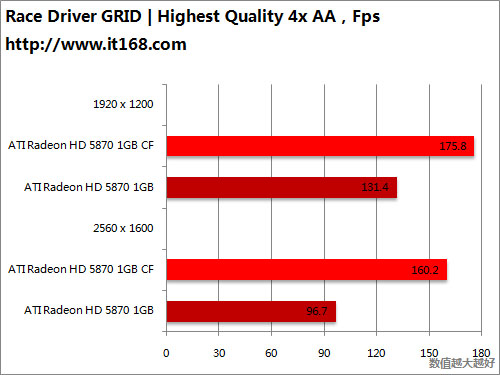

HD5870 v.s. GTX285
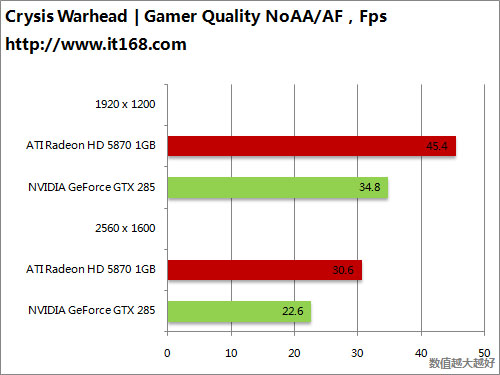
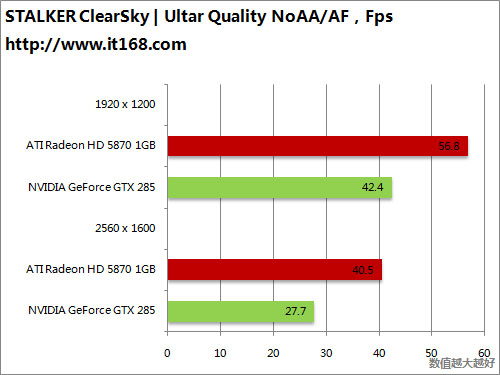
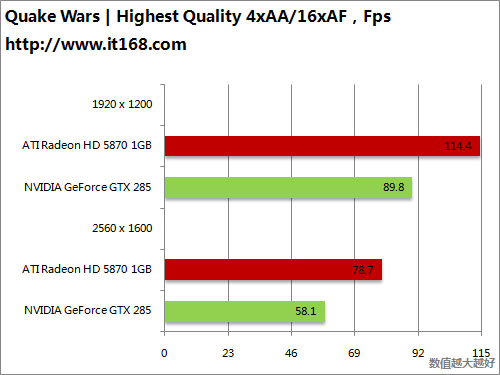
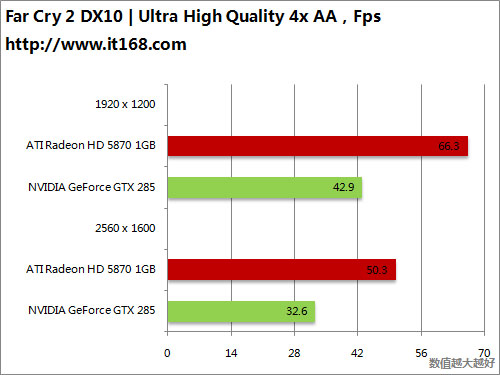
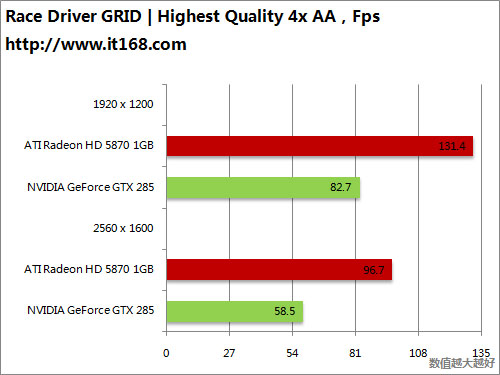
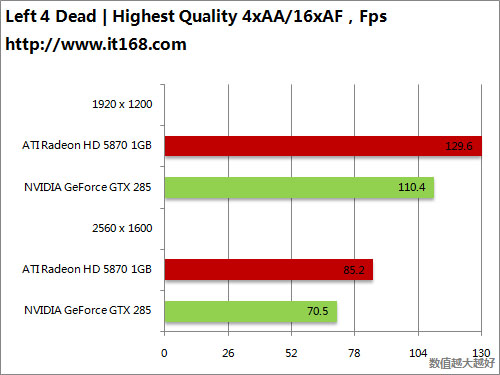
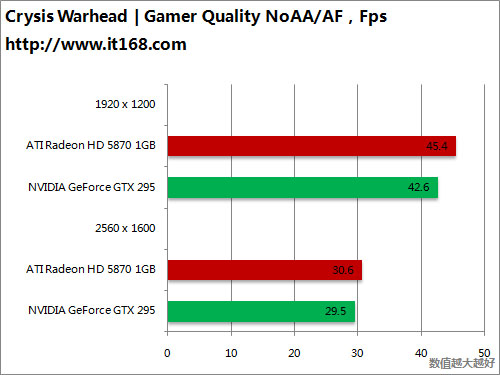
HD5870 v.s. GTX295
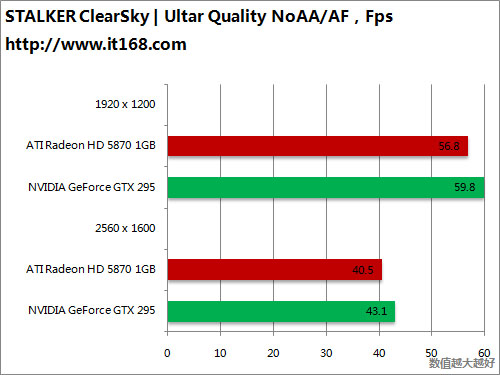

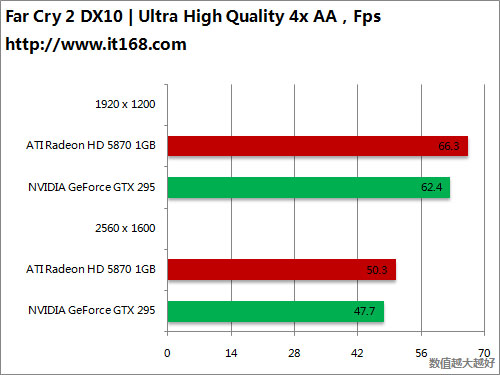
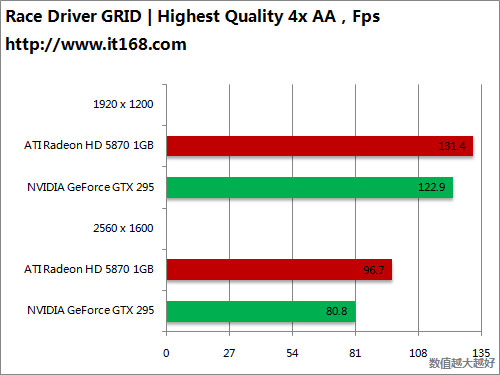
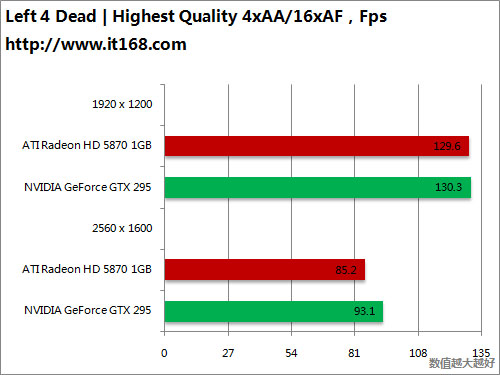
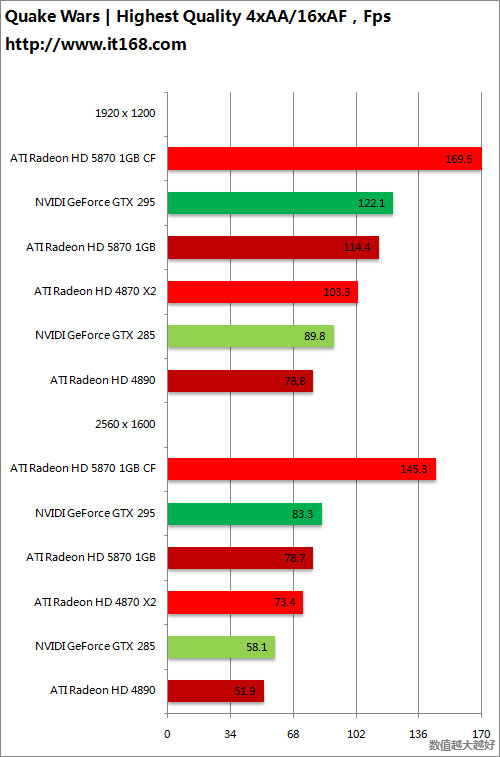
OpenGL游戏——深入敌后之雷神战争
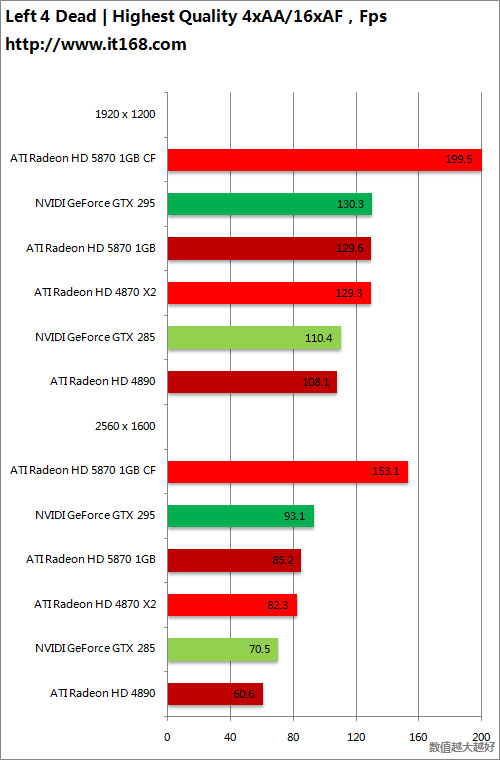
DirectX 9游戏——求生之路
DirectX 10游戏——孤岛危机之弹头
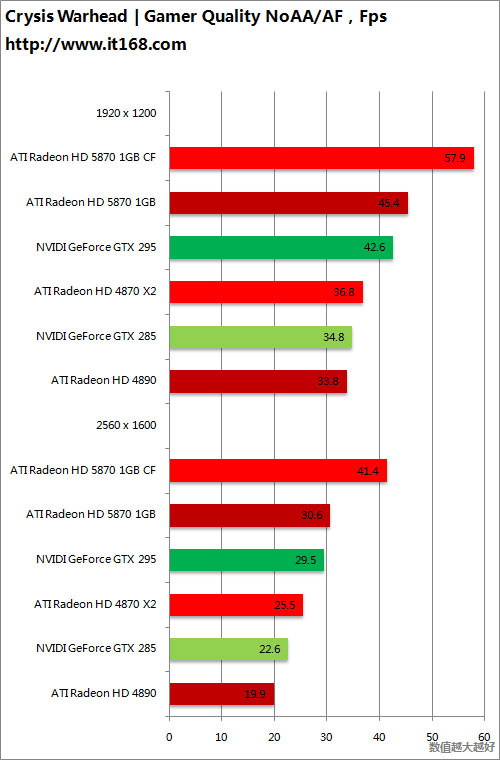
DirectX 10游戏——孤岛惊魂2

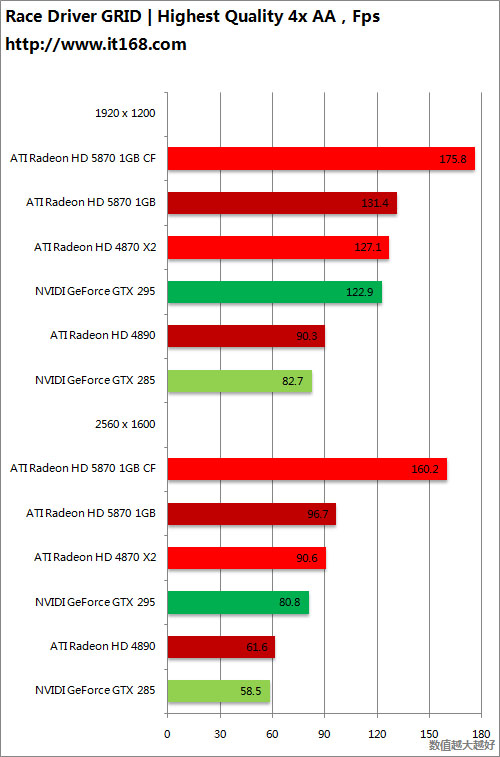
DirectX 10游戏——超级房车赛之起点
DirectX 10.1游戏——潜行者之晴空

完美无暇!无懈可击!你根本无法理解这张显卡如何设计出来的!

整个RadeonHD5870分析文章终于进入尾声,从测试看来RadeonHD5870全面超过NVIDIA的GT200系列以成事实,但更让我们佩服的是40nm工艺为RadeonHD5870带来的众多好处:RadeonHD5870在整个工作过程中无论是噪音和温度都控制得十分优秀!这甚至让人忘记它是一款全地球最强的显卡,因为在此之前几乎所有的旗舰级显卡,包括ATI和NVIDIA,给人固有的印象是又热又吵。另外成熟的PowerPlay节能功能在RadeonHD5870进一步得到完美的体现,它的待机功耗真的很低!
价格方面,目前消息证实RadeonHD5870 1G版本售价为3299元,高于GeforceGTX285低于RadeonHDGTX295,考虑到制造工艺、DirectX支持级别、性能、实用舒适性和功耗来说,该上市价格还是相当理想的,遵从了AMD“在每个价格上性能都最好”的原则。另外简化版的RadeonHD5850在国庆后将以2299元的价格上市,相信这才是NVIDIA合作伙伴最担心的一款产品,因为其性能预计仍然会比GeforceGTX285好,但价格却更便宜。
尽管目前DirectX11的实用层面还相当低,无论系统还是游戏都仅限于信息泄漏阶段,但这并不会变成阻碍RadeonHD5800系列成为经典一代的绊脚石,我们坚信历史总会是惊人的相似的——在RadeonHD9700Pro发布的时候,我们未曾能马上体验DirecrX9游戏的震撼,在Geforce8800GTX发布的时候,几乎全世界人们都还在用Windows XP,但Radeon9700Pro和Geforce8800GTX都成为了划时代级别的经典,而它们的“后代”都在未来很长的一段时间内控制了整个市场,所以RadeonHD5870诞生的意义并不仅限于这款产品本身,最大的意义在于它又再开始了一个时代!一个属于勇敢的红色大军的时代!
还记得,ATI在此之前稳坐最强性能宝座的时期,要追溯到2006年的RadeonHDX1900系列了,三年后的今日ATI终于抹去DirectX10时代的黑暗光环,但DirectX11的春天真正属于谁还不得而知。不过不管怎样,无论ATI和NVIDIA又为这个GPU发展史写下了艰辛的新篇章,我们必须感谢他们为人类的视觉享受事业带来的巨大贡献。
ATI Radeon HD5870显卡实物赏析






























