【IT168 评测】3月27日期待已久的全新一代DX11显卡GTX480/470终于发表,采用Fermi强大的显示核心提供出色的3D性能,相对于上一代的DX10显示芯片系列Fermi做出了非常大的改进,GTX480/GTX470的上市使NVIDIA在高端市场重振雄风。随着40nm制造工艺的成熟,Fermi芯片产能逐步提升,市场上Fermi的供货开始充足,Fermi的始终会存在一定的瑕疵品,通过屏蔽流处理器和显存带宽来得到规格较低的GTX470,但是部分核心甚至可能会出现不足够GTX470个完好流处理器,NVIDIA也将这部分芯片利用起来,就是我们今天的主角--GTX465。

GTX465首发测试
GTX465在6月1日正式发布,GTX465同样采用GF100显示核心,流处理器将会进一步缩减到352个流处理器,显存带宽也缩减到256bit,性能上也会和GTX470拉开一定的差距,继续将Fermi向下层市场渗透。GTX465的出现一方面可以将Fermi的瑕疵芯片进一步清理,另一方面则可以向2000元附近市场渗透,主要竞争对手是HD5830。
NVIDIA DX11显卡路线
按照NVIDIA的DX10显卡的部署计划GTX465的代号是D12U-20,可以看到是属于高端产品,而规格也和即将发布的GTX460的规格比较接近。GTX465目标市场是2000元附近的高端玩家市场,但可以看到的一点是GTX460发布后GTX465是否还会存在?GTX465采用Fermi核心在成本上可能会偏高,而Fermi的良品率是困扰NVIDIA的一个大问题,采用GF104核心的GTX460将会进一步成本降低,到时候的GTX465也有可能功成身退,GTX465的推出也是NVIDIA的权宜之计。
GTX480/GTX470/GTX465规格对比
通过规格对比可以看到GTX465的规格进一步缩水,Fermi核心的GTX480已经是进行屏蔽流处理器,GTX470进一步进行缩减,到GTX465只剩下352个流处理器,相对于完整版的Fermi的512个流处理器GTX465足足缩减了160个流处理器,缩减接近三分一。显存带宽进一步缩减到256bit,使用1024MB的GDDR5显存,显存由10颗减少到8颗成本可以进一步降低。而GTX465的核心频率和Shader频率也和GTX470一样的607/1215MHz,显存频率则降低到只有3206MHz。虽然流处理器的进一步减少,但GTX465的功耗只是相对于GTX470降低了15w,所以在产品的散热器设计上也继续沿用GTX470的散热器。

GTX465
市场定位方面GTX465定位在高端市场,价格是2188元,直接竞争对手是HD5830,价格在HD5850和HD5830之间,如果AMD将HD5850和HD5830的价格再向下调整,GTX465就会处于一个比较尴尬的位置,也许NVIDIA要考GTX460来弥补市场的空缺。
GTX465实物及参数介绍:

GTX465显示核心
GTX465采用GF100-030-A3显示核心,同样是属于Fermi核心,架构上和GTX480/GTX470基本一致,同样支持DX11。核心采用台积电40nm工艺制造,大概集成30亿个晶体管。GeforceGTX465核心拥有352个流处理器(比GTX470少96个),核心运行频率为607MHz(和GTX470一致),流处理器运行频率为1215MHz(和GTX470一致)。
显存方面,GTX480位宽为256bitBit(GTX470为320Bit),同样使用上了GDDR5显存,运行频率为3206MHz(GTX470为3348MHz),显存容量为1024MB(GTX470为1280MB)。
功耗方面,GTX470单卡功耗为200W,比上代GTX470的215W降低15W,GTX465同样采用双6pin的供电接口设计。
GTX465外观:

GTX465外观

GTX465外观

GTX465外观
GTX465正式发布了,各大厂商的GTX465也会陆续登陆市场,现在上市的GTX465都是采用公版设计,使用和GTX470一样的PCB和散热器,在供电接口方面也同样采用双6pin电源接口。

GTX465视频接口
视频接口方面同样提供双DVI+miniHDMI接口的设计,同样没有提供DisplayPort的支持。不过这样的输出接口配置也足以满足用户对各显示设备的支持。因为是测试样本的缘故,随卡并没有附带mini-HDMI转HDMI的相关线材,不过相信在正规零售版本中,各品牌的GTX480显卡都会附送mini HDMI转HDMI的转接口或者是转接线。
GTX465拆解:
GF100显示核心
GTX465的GF100核心,采用台积电40nm工艺制造,核心编号为GF100-030-A3,其中A3代表第三版样本。生产周期为2010年第13周。

三星GDDR5显存
GTX465采用三星0.5ns的GDDR5显存,8颗32Mx32Bit显存颗粒组成了1024M/256Bit的显存规格,显存频率为3206MHz

GTX465拆解

GTX465拆解拆解
由于GTX465采用和GTX470一样的PCB和散热系统,所以拆开外壳后可以看到内部的结构基本上和GTX470相差无几。

GTX465拆解
GTX465的散热器主要组成部分都安置在底板上,这个底板一方面可以起到散热的作用,另外一方面可以防止显卡由于外力或者散热器的重量造成PCB变形
散热及供电部分:

GTX465散热器

GTX465散热器

GTX465散热器
GTX465的散热片同样具备5条热管触底技术的热管,由于散热片部分并不需要象GTX480那样外露,所以并没有作镀镍处理。

PCB正反两面
完全拆除散热器后可以看到采用公版PP1025 PCB设计的GTX465显存上有2个空焊位置,显存有10颗减少到了8颗,其他各方面基本上和GTX470大同小异。

GTX465供电部分

电源管理IC
GTX465的PCB同样采用为散热风扇镂空PCB的设计,显卡的供电部分集中在PCB的尾部,供电部分仍然采用传统的铝聚合物电容+贴片电感+LFPAK封装的MOSFET,核心部分一共采用6相供电,而显存部分采用了单相供电。
GF100架构分析:图形处理集群
GigaThread引擎是NVIDIA在G80时候开始提出的一项线程调度多任务管理引擎,其角色在整个核心中起着一个任务分派的角色。G80的GigaThread引擎已经能实时管理多达12288个Thread,而在GF100架构上不仅线总程数增加了一倍,还显著性地提升了contextswitching的性能、实现并发式核心程序(concurrent kernel)执行以及改进的Thread Block调度。
同时执行多个内核+更快速的内容切换
GigaThread引擎能够从系统内存中获取指定的数据并将其拷贝到显存中。GF100采用了6个64位GDDR5存储器控制器(总共384位),便于显存高带宽存取。GigaThread引擎然后会为各个SM创建和分派线程块。单个SM反过来会将多个Warp(32个线程的群组)调度至多个CUDA核心以及其它执行单元。当图形流水线中出现工作高负载现象时,例如在Tessellation(曲面细分)以及光栅化阶段之后,GigaThread引擎还能够将工作重新分配至SM。
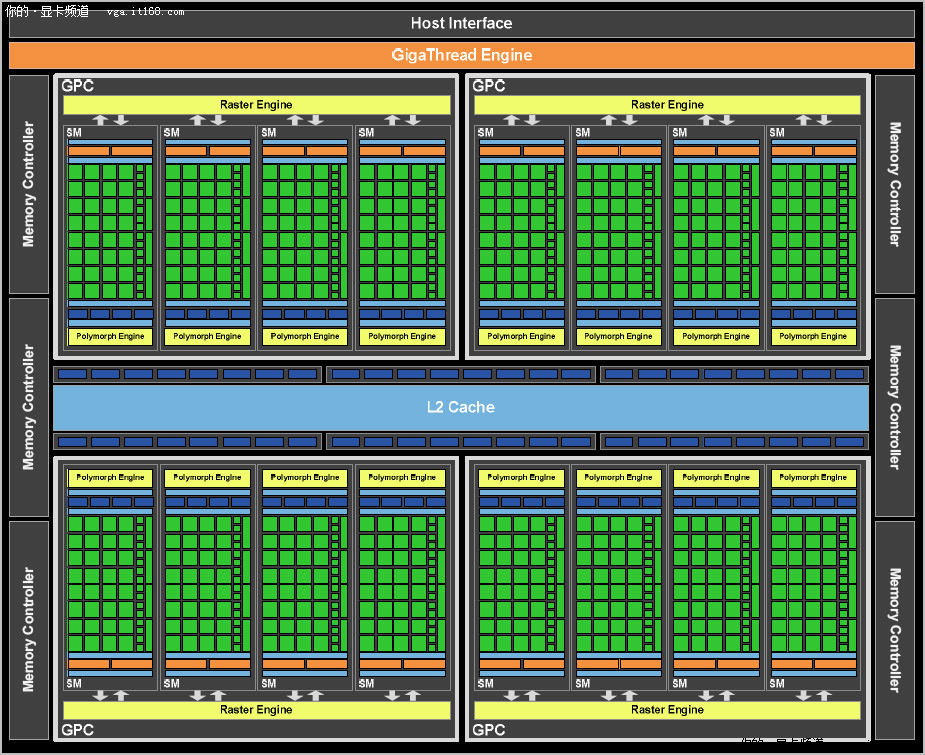
GF100核心架构组织示意图
GF100核心内部总共拥有512个CUDA核心,每32个核心构成一个SM(流式多处理器),共有16个SM。每个SM都是一个高度并行的多处理器,它们在任何时候都能够支持多达48个Warp。每个CUDA核心都是统一的处理器核心,能够执行顶点、像素、几何学以及计算内核。统一的2级高速缓存架构能够提供载入、存储以及纹理操作等服务。
GF100拥有48个ROP单元,它们可用于像素混合(Pixel Blending)、抗锯齿以及原子存储器操作。ROP单元每8个一组,共有6组。每一组均由一个64位存储器控制器来进行控制。存储器控制器、2级高速缓存、以及ROP群组全都密切关联,扩展一个单元就会自动地扩展其它部件。
GF100的主要计算单元——图形处理集群(GPC)
GF100的图形架构由大量叫做“图形处理集群”(GPC)的硬件模块构成。一个GPC包含一个Raster引擎以及最多四个SM。
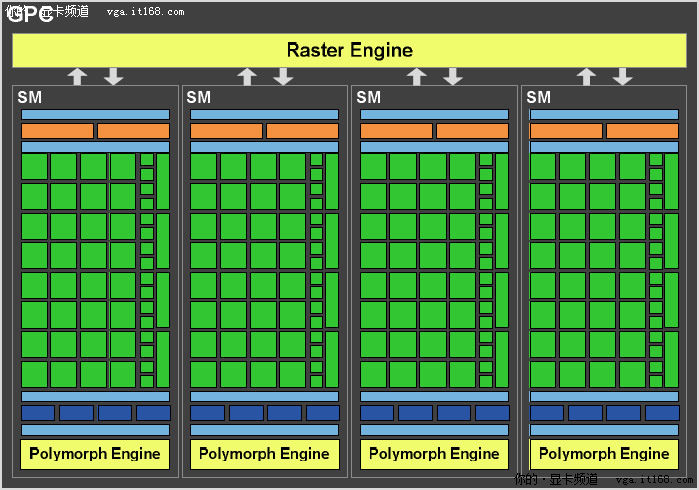
GF100的每个GPC比喻成多核CPU的其中一个核
如其名称所示,GPC囊括了所有主要的图形处理单元。它代表了顶点、几何、光栅、纹理以及像素处理资源的均衡集合。除了ROP功能以外,GPC可以被看作是一个自给自足的GPU,而一颗GF100拥有四个GPC!
GT200架构的每个TPC中,每三个SM共享一个纹理单元
在GF100之前的GPU中,SM与纹理单元在一种叫做“纹理处理集群”(TPC)的硬件模块中聚集在一起。而在GF100中,每一个SM都拥有四个专用独立的纹理单元,这样就不再需要TPC了。
GF100图形处理集群改进:PolyMorph引擎
GF100的主要高级硬件模块——GPC
GPC是GF100的主要高级硬件模块。它拥有两项重要的创新:一个用于三角形设置、光栅化以及Z坐标压缩(Z-cull)的可扩展Raster引擎,一个用于顶点属性提取与Tessellation(曲面细分)的可扩展PolyMorph引擎。Raster引擎驻留在GPC当中,而PolyMorph引擎则驻留在SM中。
细分曲面渲染过程示意图
虽然可编程着色让PC游戏能够在每像素特效上与电影相媲美,但是在几何学逼真度上PC游戏还差得很远。当今非常先进的PC游戏在每一帧中运用一两百万个多边形。相比之下,计算机生成的电影中每一帧通常会运用数以亿计的多边形!在解决几何学逼真度这一问题上,NVIDIA把目光投在了电影上获得启发。电影中人物的精细画质归功于两种关键技术:Tessellation(曲面细分)以及Displacement Mapping(贴图置换)。
Tessellation耗费大量的几何运算
Tessellation(曲面细分)的使用从根本上改变了GPU图形负荷的平衡。凭借Tessellation(曲面细分),特定帧中的三角形密度能够增加数十倍,但这给设置于光栅化单元等串行工作的资源带来了巨大压力。为了保持较高的Tessellation(曲面细分)性能,有必要重新平衡图形计算流水线。
为了便于实现较高的三角形速率,NVIDIA设计了一种叫做“PolyMorph引擎”的可扩展几何引擎。每16个PolyMorph引擎均拥有自己专用的顶点获取单元以及Tessellator,从而极大地提升了几何性能。与之搭配,每个GPC还配有一个并行Raster引擎,它们在每个时钟周期内可设置最多四个三角形。同时,它们还能够在三角形获取、Tessellation(曲面细分)、以及光栅化等方面实现巨大性能突破。
PolyMorph引擎:
PolyMorph引擎拥有五个阶段:顶点获取、Tessellation(曲面细分)、观察口转换、属性设置以及流式输出。每个阶段中所运算得出的结果均被发送至一个SM。该SM能够执行游戏的着色程序、将结果返回至PolyMorph引擎中的下一个阶段。在所有阶段都完毕之后,结果会被传递给Raster引擎。
PolyMorph引擎
第一个阶段是从一个全局顶点缓冲区中获取顶点。所获取的顶点于是被发送至SM,以进行顶点着色以及外壳着色。在这两个阶段中,顶点从一个物体空间转变成了世界空间,而且还算出了Tessellation(曲面细分)所需的参数(例如Tessellation(曲面细分)系数)。Tessellation(曲面细分)系数(或LOD)被发送至Tessellator。
在第二个阶段中,PolyMorph引擎读取Tessellation(曲面细分)系数。Tessellator将修补面(控制点网格所定义的光滑表面)分成小方块并输出许多顶点。修补(u、v)值定义了网格以及形成网格的连接方式。
全新的顶点被发送至SM,域着色器与几何着色器均在这里执行。域着色器能够根据外壳着色器与Tessellator的输入来运算每个顶点的最终位置。在本阶段中,通常会附上一个Displacement Mapping(贴图置换)以提升修补面的细节表现。几何着色器能够执行任何后期处理、按需增加或删除顶点以及基元。结果最终将被发回至Tessellation(曲面细分)引擎。
在第三个阶段,PolyMorph引擎会执行观察口转换以及视角校正。接下来就是属性设置,把后期观察口顶点属性转变成了平面方程,以进行高效的着色器评估。最后,可以选择将顶点“流出”至存储器,使其能够用于更多处理。
在之前的架构上,固定功能的操作由单个流水线来执行。在GF100上,固定功能与可编程操作全部都实现了并行化,从而极大地提升了性能。
GF100图形处理集群改进:Raster引擎
在PolyMorph引擎处理完基元之后,它们就被被发送至光栅(Raster)引擎。为了实现较高的三角形吞吐量,GF100采用四个Raster引擎并行工作的方式。
Raster引擎
Raster引擎由三个流水线阶段组成。在边缘设置阶段中,可提取顶点位置、计算三角形边缘方程。没有朝向屏幕方向的三角形都通过背面剔除而删掉了。每一个边缘设置单元在一个时钟周期中最多都能够处理一个点、线或三角形。
光栅器(Rasterizer)为每一个基元而运行边缘方程并计算像素的覆盖。如果开启了抗锯齿功能,那么就会为每一个多采样以及覆盖采样执行覆盖操作。每一个光栅器在每个时钟周期内均可输出8个像素,整个芯片每个时钟周期内总共可输出32个光栅化的像素。
光栅器所生成的像素将被发送至Z坐标压缩(Z-cull)单元。Z坐标压缩单元获取像素图块(Pixel Tile)并将图块中像素的深度与显存中的现有像素进行比较。完全处于显存像素后面的像素图块将从流水线中剔除,从而就不再需要进一步的像素着色工作了。
PolyMorph引擎与Raster引擎加入对GF100的GPC架构具有重大意义:
Tessellation(曲面细分)在实际中应用
PolyMorph引擎与Raster引擎的加入让GPC架构在平衡图形流水线方面实现了巨大突破。Tessellation(曲面细分)需要全新级别的三角形与光栅化性能。PolyMorph引擎为三角形、Tessellation(曲面细分)以及流出(Stream Out)等方面实现了大幅性能提升。四个并行Raster引擎在三角形设置与光栅化方面能够提供持久的高吞吐量。通过为每一个SM配备一个专用的Tessellator、为每一个GPC配备一个Raster引擎,GF100所能够实现的几何性能可达GT200的8倍。
GF100架构分析:第三代流处理器群(SM)
第三代流处理器群(SM)
从G80到GT200再到GF100,NVIDIA GPU的流处理器群(SM)已经升级至第三代,每一代各部分单元的配比都不一样。第三代SM在架构上引入了多项革新,使其不仅成为迄今为止最强大的SM,而且还是可编程性最强、效率最高的SM。
GF100架构特色
GF100架构每个SM都有32个CUDA处理器,达到了之前SM中处理器数量的四倍。GF100的CUDA核心专为在着色器的任何负荷下均实现最高性能以及最高效率而设计。通过采用全标量架构,无论输入向量尺寸如何,都能够实现全部性能。Z缓冲区(1D)或纹理存取(2D)方面的操作均可充分利用GPU资源,再不受旧有的固定4D算法的约束。
每一个CUDA处理器都拥有一个完全流水线化的整数算术逻辑单元(ALU)以及浮点单元(FPU)。GF100采用了全新的IEEE754-2008浮点标准,能够为单精度以及双精度算术提供融合的乘法加法(FMA)指令。FMA在一个最终的四舍五入步骤中即可完成乘法与加法运算,改进了乘法加法(MAD)指令,在加法中不会损失精度。FMA在处理紧密重叠的三角形时能够最大限度地减少渲染错误。
在GF100中,全新设计的整数ALU支持所有指令全32位精度,符合标准编程语言的要求。整数ALU还经过了优化,可有效支持64位以及更高精度的运算。它支持各种指令,其中包括Boolean、移位、移动、比较、转换、位字段提取、位反向插入(Bit-reverse Insert)以及种群统计。
GF100流处理器群的载入单元与存储单元:
每一个SM都拥有16个载入/存储单元,从而在每个时钟周期内均可为16个线程运算源地址与目标地址。支持的单元能够将每个地址的数据载入和存储到高速缓存或DRAM中。
GF100流处理器群的四个特殊功能单元:
特殊功能单元(SFU)可执行抽象的指令,例如正弦(sin)、余弦(cosine)、倒数和平方根。图形插值指令也在SFU上执行。每个SFU在一个时钟周期内针对每个线程均可执行一条指令,一个Warp(32个线程)的执行时间可超过八个时钟周期。SFU流水线从分派单元中分离出来,让分派单元能够在SFU处于占用状态时分发给其他执行单元。复杂的程序着色器在特殊功能专用硬件上的运行优势尤为明显。
GF100流处理器群的双Warp调度器
GF100架构的每个SM可对32个为一组的并行线程(又叫做Warp)进行调度。每个SM拥有两个Warp调度器以及两个指令分派单元,这样,就能够同时发出和执行两个Warp。GF100的双Warp调度器可选出两个Warp,从每个Warp发出一条指令到16个核心、16个载入/存储单元或4个特殊功能单元。因为Warp是独立执行的,所以GF100的调度器无需检查指令流内部的依存关系。通过利用这种优秀的双指令执行(Dual-issue)模式,GF100能够实现接近峰值的硬件性能。
双Warp调度器
大多数指令都能够实现双路执行,两条整数指令、两条浮点指令或者整数、浮点、载入、存储的混合指令以及SFU指令均可同时执行。双精度指令不支持与其它指令同时分派。
GF100流处理器群的纹理单元
GF100的每个SM中有独享的4个纹理单元
GF100架构每个SM都拥有四个纹理单元。每个纹理单元在一个时钟周期内能够计算一个纹理地址并获取四个纹理采样。返回的结果可以是经过过滤的也可以是未过滤的。支持的模式包括双线性、三线性以及各向异性过滤模式。GF100的目标是通过提升效率来提升纹理性能。通过将纹理单元搬到SM当中实现了这一目标,提升了纹理高速缓存的效率、实现了更高的时钟频率。
GT200架构的每个TPC中,每三个SM共享一个纹理单元
在以往的GT200架构中,最多三个SM共享一个纹理引擎,该引擎含有八个纹理过滤单元。而在GF100架构中,每个SM都拥有自己专用的纹理单元以及一个专用纹理高速缓存。而且,纹理单元的内部架构还得到了大幅增强。在阴影贴图、屏幕空间环境光遮挡等实际使用情况中,净效应就是所实现的纹理性能得到了大幅提升。
GF100专用的1级纹理高速缓存经过重新设计,可实现更高的效率。而且,通过配备统一的2级高速缓存,纹理可用的最大高速缓存容量达到了GT200的三倍,为纹理密集的着色器提升了命中率。之前架构上的纹理单元以GPU的核心频率工作。在GF100上,纹理单元的运行频率与SM同步,从而在单元数量相同时提升了纹理性能。
四偏置点Gather4
GF100的纹理单元还新增了对DirectX 11中BC6H与BC7纹理压缩格式的支持,从而减少了HDR纹理与渲染器目标的存储器占用。纹理单元通过DirectX 11的四偏置点(Four-offset)Gather4特性,还支持抖动采样。这样一来,单一纹理指令就能够从一个128×128的像素网格中获取四个纹理像素。GF100在硬件上采用了DirectX 11四偏置点Gather4,大大加快了阴影贴图、环境光遮挡以及后期处理算法的速度。凭借抖动采样,游戏就能够高效地执行更加平滑的软阴影或定制纹理过滤器。
GF100流处理器群可调配的共享存储器与L1缓存
作为一种高速、可编程的片上存储器,共享存储器是第一代CUDA架构中的一项重要架构创新。通过促进线程间的通信,共享存储器让各种各样的应用程序均能够在GPU上高效地运行。从此共享存储器便被所有主要的GPU计算标准与同类架构所采用。
可调配的共享存储器与L1缓存
在GF100架构中,每个SM均包含了一个专用的1级高速缓存。1级高速缓存能够起到与共享存储器互补的作用,共享存储器能够为明确界定存储器存取的算法提升存储器存取速度,而1级高速缓存则能够为这些不规则的算法提升存储器存取速度。在这些不规则算法中,事先并不知道数据地址。
每个SM均拥有64KB容量的片上存储器,这部分存储器可配置为16KB的1级高速缓存外加48KB共享存储器,或配置为16KB共享存储器外加48KB的1级高速缓存,这就是可调配性。
对于图形程序,GF100能够利用16KB的1级高速缓存配置。1级高速缓存的作用是充当用于寄存器溢出的缓冲区,让寄存器的使用能够实现不俗的性能提升。而如果针对计算程序,1级高速缓存以及共享存储器让同一个线程块中的线程能够互相协作,从而促进了片上数据广泛的重复利用并减少了片外的通信量。共享且可调配的存储器是使许多高性能CUDA应用程序成为可能的重要促成因素。
GF100架构分析:高速二级缓存
GF100拥有一个768KB的统一2级高速缓存,该缓存可以为所有载入、存储以及纹理请求提供服务。2级高速缓存可在整个GPU中提供高效、高速的数据共享。物理效果解算器、光线追踪以及稀疏数据结构等事先不知道数据地址的算法在硬件高速缓存上的运行优势尤为明显。后期处理过滤器需要多个SM才能读取相同的数据,该过滤器与存储器之间的距离更短,从而提升了带宽效率。
GF100的高速缓存架构让各流水线阶段之间可以高效地通信
统一的高速缓存比单独的高速缓存效率更高。在不统一的高速缓存设计中,即使一个高速缓存被程序过多地预订,它也无法使用其它高速缓存中未贴图的部分。高速缓存的利用率将时钟低于理论峰值。GF100的统一2级高速缓存可在不同请求之间动态地平衡负载,从而充分地利用高速缓存。2级高速缓存取代了之前GPU中的2级纹理高速缓存、ROP高速缓存以及片上FIFO。
GF100与GT200高速缓存架构的对比
与只读的GT200 2级高速缓存相比,GF100的2级高速缓存既能读又能写,而且是完全一致的。我们采用了一种优先算法来清除2级高速缓存中的数据,这种算法包含了各种检查,可帮助确保所需的数据能够驻留在高速缓存当中。
GF100架构分析:优化8xAA的ROP与32xAA支持
提升抗锯齿能力的新型ROP单元——
GF100的ROP子系统经过重新设计,可提升吞吐量与效率。一个GF100 ROP分区包含8个ROP单元,数量比上一代架构翻了一倍。每个ROP单元在一个时钟周期内均能够输出一个32位整数像素,一个FP16像素需要两个以上的时钟周期,一个FP32像素需要四个以上的时钟周期。原子指令性能也得到了大幅提升,相同地址的原子操作执行速度最高可达GT200的20倍,邻近存储区的操作执行速度最高可达7.5倍。
抗锯齿性能对比
在GF100上,由于压缩效率的提升以及更多ROP单元能够更有效地渲染这些无法被压缩的较小基元,因此8倍速多重采样抗锯齿(MSAA)的性能得到了大幅提升。当压缩不起作用时,场景中几何逼真度的提升更加需要ROP单元良好地运行。
支持高达32x的覆盖采样抗锯齿(CSAA)——
支持高达32x的覆盖采样抗锯齿
GF100还新增了一种新型32倍速覆盖采样抗锯齿(CSAA)模式,该模式能够提供最高图像质量并利用“透明至覆盖”(Alpha-to-Coverage)来为当今游戏进一步提升几何逼真度。
GT200与GF100最高CSAA下的画质对比
由于受到API与GPU计算能力的限制,当今的游戏能够渲染的几何图形数量还很有限。叶子的渲染是一个尤其突出的难题。针对叶子的一种常用技术就是创建一个包含许多树叶的透明纹理公告板,利用“透明至覆盖”来除去树叶之间的缝隙。覆盖采样的数量决定了边缘的画质。如果只有四个覆盖或八个采样,那么将会出现非常糟糕的锯齿以及镶边现象,尤其是在纹理靠近屏幕的时候。采用32倍速覆盖采样抗锯齿(CSAA),GPU共有32个覆盖采样,从而最大限度减少了镶边效果。
更强的透明多重采样(TMAA)
更强的透明多重采样(TMAA)
透明多重采样(TMAA)也能够从CSAA中获益匪浅。由于“透明至覆盖”不在DirectX 9 API当中,所以DirectX 9游戏无法直接使用“透明至覆盖”。而TMAA恰恰对这样的游戏有所帮助。取而代之的是,它们采用了一种叫做“透明测试”的技术,该技术能够为透明纹理产生硬边缘。TMAA能够转换DirectX 9应用程序中旧的着色器代码,使其能够使用“透明至覆盖”。而“透明至覆盖”与CSAA相结合,能够生成大幅提升的图像质量。
GF100架构分析:面向图形方面的各种计算
面向图形方面的各种计算
计算机图形是一系列具有无数种途径的多样化问题。光栅化、光线追踪以及Reyes都是为人们所广泛认可的通用渲染算法。在每一种渲染风格中,都存在着针对各种子问题的不同解决方案。迄今为止,GPU已经专为光栅化而进行了设计。随着开发人员不断探索全新的方式来改进其图形引擎,GPU将需要在各种不断发展的图形算法上实现出色的性能。
除了渲染游戏画面,物理、人工智能、光线追踪等众多计算都是GPU计算的范畴
在游戏当中,每一帧都会出现渲染算法切换,这一点使其性能很难达到灵敏帧速率的要求。GF100将渲染算法切换的时间缩短至约20微妙,使其能够在每帧多个内核之间执行精细的上下文切换。例如,一款游戏可以使用DirectX 11来渲染场景、切换至CUDA以实现选择性光线追踪、调用一个DirectCompute内核来执行后期处理以及利用PhysX执行流体模拟。
将来诸多的游戏计算都可以利用GPU进行:
新渲染算法
——可获得精确发射与折射效果的光线追踪
——用于精细贴图置换与高品质抗锯齿的Reyes
——用语立体数据模拟的立体象素渲染
图象处理算法
——具有精确焦外聚光点的顶制景深
——用于高级HDR渲染的直方图
——用于高级模糊及锐化效果的定制过滤器
物理效果模拟
——用于高级流体模拟的平滑粒子流体力学
——用于精细烟雾与流体特效
——物理学物体广泛应用
大量游戏人物的人工智能算法
大量游戏人物的人工智能算法
另外,随着开发人员越来越多地将GPU应用于通用用途,在编程语言以及调试方面提供更好的支持就变得愈加重要。GF100是首款完全支持C++的GPU(图形处理器),C++是游戏开发人员所选用的一种编程语言。为了使向GPU编程的过渡过程变得轻而易举,我们还开发了Nexus,Nexus是一种面向GPU的微软Visual Studio编程环境。加上这些能够提供更好调试支持的全新硬件特性,开发人员将能够在GPU上轻松开展开发工作,正如他们在CPU上开发应用程序一样。
GF100图形计算:光线追踪与流体力学
GF100图形计算:光线追踪
光线追踪
无论是光线追踪本身还是光线追踪与光栅化的结合都行业视为是图形处理的未来发展趋势,随着GF100问世,交互式的光线追踪计算首次在PC上成为可能。
反复的光线追踪计算花费大量的运算资源
过去在GPU难以高效运行的难题当中,光线追踪一直是很有代表性的一个。光线追踪反复循环的工作让GPU反复地计算,而且光线方向具有不可预测性,需要大量随机存储器存取,为高效灵活处理,GPU一般以线性块的方式存取储存器。
GF100面向图形方面的计算能力,在设计其间就专门把光线追踪考虑在内了,GF100是首款在硬件上支持光线追踪循环计算的GPU,能够执行高效的光线追踪和大量的其他图形算法。通过灵活可调配存储器的存取性能,GF100的1级和2级高速缓存大幅提升了光线追踪的效率。
光线追踪
GF100不仅在标准光线追踪中有优势,并且在路径追踪等高级全局照明算法中也有不错的表现。路径追踪采用大量光线来收集场景中的环境光照信息。上图为NVIDIA借助OptiX技术的路径追踪所渲染的布加迪威龙,OptiX技术能很容易整合到众多的游戏渲染引擎中,从而实现近乎真实照片般的逼真效果。
GF100图形计算:流体力学
流体力学
逼真的流体效果模拟长期以来一直被用于电影中,《终结者2:审判日》中的T-1000角色正是由计算机生成的“液态金属”所打造出来的效果。对海量水体的模拟效果是完成《2010》中灾难场景的重要组成部分。在PC游戏领域,虽然游戏设计师很渴望可以利用类似效果打造出更逼真的游戏画面,但流体模拟的复杂计算阻碍了他们在实时应用程序中应用。
流体力学
GF100是首款能够满足高效流体模拟所需性能的GPU,GF100搭配一款改进型SPH解算器就能够让游戏设计师在整个游戏环境中加入高品质SPH流体效果。GF100能够模拟每帧128000个以上的SPH粒子,足以支持大量的水和各种基于流体的特效。例如可用于为雨水建模,制作出自然形成的水花、旋涡和溢流效果。
SPH算法一般不利用共享存储器,共享存储器在上一代架构中限制了性能。GF100强大的高速缓存架构大幅减少片外存储器的通信量,从而能够在不耗尽存储器带宽的情况下模拟大量粒子效果。
GF100的多屏幕3D环绕立体幻镜技术
GF100的多屏幕3D环绕立体幻镜技术
除了画面外,多屏显示似乎是DX11时代的一个新方向,ATI的Eyefinity宽域技术最多支持6屏幕输出,使全线HD5000系列显卡至少能支持3屏输出。而NVIDIA的GF100架构在多屏输出的基础上还结合了自己的技术特性,推出了环绕立体幻镜技术。
GF100的多屏幕3D环绕立体幻镜技术
三屏幕3D立体幻镜的渲染能力最高需要每秒7.46亿个象素,这个数字是上代优异游戏配置的三倍,加上Tessellation、计算着色和物理运算等负载之后,三屏幕3D立体幻镜玩游戏时对GPU的要求达到前所未有的高度,所以组建三屏幕3D立体幻镜必须配搭GTX400系列或GTX200系列显卡的SLI系统。
3D幻镜及3D显示器
另外,根据NVIDIA介绍,即使玩家没有配备3D幻镜及3D显示器,也可以通过三台普通显示器实现多屏环绕效果,最高可支持三台2560x1600分辨率的显示器组成多屏环绕显示系统,不过组建这样的多屏显示系统仍然需要两块或更多的NVIDIA显卡组成SLI配置。
边框校正
边框阻隔是多屏幕显示无可避免的问题,ATI的Eyefinity宽域技术在初期也不具备边框校正功能,而后来在催化剂10.3驱动中才加入边框补偿的功能。而NVIDIA的多屏幕3D环绕立体幻镜技术同样支持类似的技术。边框校正能使多显示器画面连接后显得具连贯性,玩家就好象坐在座舱里面往外看风景一样,窗框挡住了部分视线,这样的体验更贴近真实。
关于曲面细分和贴图置换的概述
关于曲面细分和贴图置换的概述
虽然Tessellation(曲面细分)以及Displacement Mapping(贴图置换)不是什么新型渲染技术,但是直到目前,电影行业还大都一直在运用这两项技术。随着DirectX 11与NVIDIA GF100的推出,开发人员将能够利用这些强大的技术来打造游戏应用程序。在游戏开发与高品质实时渲染上,我们将介绍一下Tessellation(曲面细分)以及Displacement Mapping(贴图置换)的一些特性与优势。
曲面细分技术
物体与人物等游戏内容一般需要用Mudbox、ZBrush、3D Studio Max、Maya或SoftImage等建模软件包来创建。这些软件包能够提供基于Displacement Mapping(贴图置换)表面的工具来辅助艺术家创建细腻的人物与环境。现在,艺术家必须手动创建各种细腻程度的多边形模型,以满足游戏中各种渲染场景所需、达到保持可玩性帧速率的目的。这些模型就是带有相关纹理贴图的三角形网格,而这些纹理贴图则是正确着色所需要的。当游戏中运用到这些模型时,每一帧的模型信息都通过主接口(Host Interface)发送给GPU。由于PCI Express总线的带宽限制,游戏开发商倾向于使用相对简单的几何模型以及目前GPU最保守的几何学吞吐量。
曲面细分和贴图置换
即使在最好的游戏中,也会因为现有图形API以及GPU的限制而存在几何学伪像。在下列《FarCry2》游戏截图中即可看到复杂几何图形的折衷表现结果。手枪皮套有太多的刻画面,皮带的分割感太强。瓦楞屋顶本应看起来有波纹感,但是实际上是带有条纹纹理的平面。最后,正如游戏中的大多数人物一样,这个人戴着一顶帽子,细心地避开了渲染头发所涉及的复杂度。
利用基于GPU的Tessellation(曲面细分),游戏开发人员能够发送物体或人物的紧凑型几何表现形式,而Tessellator单元则能够为特定场景生成合适的几何学复杂度。现在我们来看看更加细腻的细节表现,研究一下Tessellation(曲面细分)与Displacement Mapping(贴图置换)结合使用的特点与优势。
曲面细分和贴图置换
让我们来看一看上面的人物。我们能够看到,在左边的图像使用了四边形网格来勾勒人物的大致轮廓。即使与一般的游戏内容相比,这种表现形式占用空间也是非常少的。中间这幅人物图像是对左侧图像进行了精细Tessellation(曲面细分)与描绘的结果。因此它拥有了非常光滑的外观,没有因几何形状的限制而形成多个刻画面。不幸的是,这个人物虽然外表光滑,但是与粗糙的网格相比,细节部分并无改善。右侧的图像是对中间图像附上了一个Displacement Mapping(贴图置换)的效果。这个人物拥有可媲美电影制作中的丰富几何细节。
测试平台:
测试平台
测试说明:
测试项目方面,我们舍弃了老旧的3Dmark06,只采用3Dmark Vantage作为理论性能的项目。而游戏方面若游戏有自带或者第三方Benchamark软件则使用,若没有的则使用FRAPS监查帧数变化最平均值,务求尽量获得最准确的数据;由于测试对象为NVIDIA的中高端显卡,我们直接采用2560*1600和1920*1200两个高分辨率进行性能测试,所以部分要求强度相对较低的游戏,开启8xAA全屏抗锯齿的方式进行测试。
Gefroce GTX465 GPU-Z信息
运行中的GTX465平台
理论性能测试----3Dmark Vantage v102
3Dmark Vantage v102
3DMark Vantage是专门针对微软DX10 API的综合性基准测试工具。 此前的3DMark最终结果只有一个简单的分数,3DMark Vantage一个全新特性是引入了四种不同等级的参数预设(Preset),按照画质等级划分成了入门级(Entry,E)、性能级(Performance,P)、高端级(High,H)、极限级(Extreme,X)四类。测试结果改成了“字母等级”加“数字”的组合形式。
Performance模式:
测试结果
3Dmark Vantage的理论测试中,在主流强度的Performance模式里面关闭物理的GTX470/465都分别稍微落后于HD5850与HD5830,这主要原因在于低强度下更考验的是显卡的运行频率,这方面HD5800系列占了便宜。
Extreme模式:
测试结果
而到了高强度的Extreme模式,GTX470终于展现了其强大的性能,反超ATI的HD5850。不过GTX465在理论性能测试中并没有给我们太大的惊喜。
DirectX11 DEMO----Unigine_Heaven-2.1《天堂 2.1》
Unigine_Heaven-2.1《天堂 2.1》
Unigine放出了其最新的DX11性能测试程序Unigine Heaven的2.1版本,Unigine Heaven 2.0支持DX9、10、11,并新增对OpenGL的支持,并进一步加重了tessellation负担,游戏支持高级SSAO技术,并能精确物理模拟的容积云和带有光线散射的动态天空.
测试结果
由于GF100架构对曲面细分技术进行了大量的支持和优化,所以在天堂2.1中,凭借架构的优势GTX465和GTX470一举超越了HD5850/5830。
DirectX10游戏----Crysis Warhead《孤岛危机:弹头》
Crysis Warhead《孤岛危机:弹头》
Crysis Warhead《孤岛危机:弹头》全面强化Nanosuit作战服的崭新能力与操作体验,新加入的“Advanced AI”技术将把游戏互动体验提升到一个更高的高度。玩家将在游戏中继续借助Nanosuit与外星种族展开最后的生死搏斗,与众多新增角色一同进行惊心动魄的冒险之旅。无可否认,Crysis Warhead的配置需求代表了将来很长一段时间DX10游戏的基本配置要求,很具参考性。
测试结果
可以看到新一代的中高端级显卡中可以在24寸加4XAA的环境下,以30的平均FPS畅玩“显卡危机”了。
DirectX10游戏----FarCry2《孤岛惊魂2》
FarCry2《孤岛惊魂2》
《Far Cry 2》游戏采用了强大的技术和卓越的声音视觉效果共同创造了一个艳丽的虚拟世界,其中包含了众多聪明的敌人、与现实相贴切的枪械和车辆以及它们的损坏方式。与此同时,其快节奏的游戏体验也给人以刺激的挑战。
测试结果
打开抗锯齿的《孤岛惊魂》是对显卡ROP性能最敏感的一个游戏,由这项测试中可以看到优化ROP性能后的GTX400性能十分强劲,即使是中高端的GTX465也能一举超过HD5850。
DirectX10游戏----H.A.W.X《鹰击长空》
H.A.W.X《鹰击长空》
鹰击长空(Tom Clancy's H.A.W.X)由Ubisoft的Bucharest Studio负责开发,玩家可以在游戏中驾驶超过50种飞机进行空战.游戏的背景时间设定在2012年,那时的世界正越来越依赖于私人的军火公司(PMCs)。随着PMCs逐渐强大,世界正走向全球冲突的悬崖。这听起来好像是个足够充分的理由让玩家跳进自己的战斗机去干掉那些坏蛋。HAWX提供了名为“强化真实系统”(ERS)的特性,该系统甚至能够让一般的飞行员感觉像是Iceman。ERS包括雷达,来袭导弹探测,防坠毁系统,损害控制系统,战术地图,信息中继,武器弹道控制和允许玩家控制AI中队的指令。开启所有的辅助模式后,ERS将为飞行员提供最大限度的安全保障。想象一下好比在赛车游戏中开启所有辅助模式后的效果吧。虽然关闭辅助模式后玩家可以在控制上获得更多的自由,但没有了ERS的全部保障措施也相应的提高了风险。
测试结果
鹰击长空是一款很具代表性的DX10.1的游戏,同样也是一款相当考验显卡性能的游戏。在测试中看同,由于架构上的优势,GTX465/470系列分别对手。
DirectX10游戏----World in Conflict《冲突世界4》
World in Conflict《世界冲突》
《世界冲突》(World in Conflict)是一款以虚拟全球冷战为故事背景的RTS游戏,PC版游戏画面真正达到高清大片的水准。游戏以发生于21世纪的虚拟全球战争为背景,是Vivendi旗下著名的Massive Entertainment公司(代表作有《地面控制》系列)最新开发的产品。
测试结果
在比较传统的《世界冲突》(World in Conflict)游戏中,,GTX400系列显卡同样凭借着强大的架构优势领先于对手A卡,而GTX465的成绩更是相对接近HD5850。
DirectX10游戏----Resident Evil 5《生化危机5》
Resident Evil 5《生化危机5》
《生化危机5》的故事是在一片酷热沙漠中的无名小镇上展开的,根据竹内润的介绍,这个地区发生了类似种族冲突的纷争,居民们情绪激动且各种暴力事件频发。与真实世界中发生种族冲突乃至仇杀的地区一样,这里充满了混乱,社会失去了本来的秩序,正义和邪恶的界限已经变得模糊不清。我们的主人公克瑞斯,就是在这样一个背景下前往这个充满动荡的地区展开调查的。
测试结果
生化危机5中低分辨率下各卡的表现都算中规中距,不过随着分辨率提高,ATI HD5800系列的表现有所提升,2560X1600分辨率下HD5850反超了GTX470,同样HD5830也超过了GTX465.
DirectX9游戏----STREET FIGHTER 4《街头霸王4》
STREET FIGHTER 4《街头霸王4》
在经历了10年岁月、两代主机更迭交替、无以计数的传闻和猜测后,Capcom公司的格斗游戏名作《街头霸王》系列的最新续作《街头霸王4》终于向玩家们显露出他的真实面貌。本作将承袭系列作传统2D玩法,并采用最新的3D绘图技术,以更华丽的方式重现原作独特的2D绘图风格.
测试结果
根据我们以前的测试经验得知《街头霸王4》一直都是AMD显卡的传统强项,但GTX400的到来改写了这个。可以看到在街头霸王4中,GTX465的性能表现已经很接近HD5850.
DirectX9游戏----StarCraft 2 beta《星际争霸2 beta》
StarCraft 2 beta《星际争霸2 beta》
2月18日——《星际争霸2》终于展开了万众期待的全球范围的封闭测试,来自世界各地的数千名受到暴雪邀请的游戏玩家才有幸参与封闭测试。星际2延续了星际1传统的打法,同样是以人海战术和兵种的搭配为重点。既然用人海战术,那么对系统整机的要求还是非常高的,显卡性能差点就会被KO。
测试结果
千元以上的高端卡在星际2中基本性能差别不大,由于暴雪的游戏在3D图形效果方面并非特别复杂,所以该测试频率成了关键因素。
DirectX9游戏----NEED for speed:shift《优品飞车13:变速》
NEED for speed:shift《优品飞车13:变速》
《优品飞车13》将偏向于赛车的真实感,游戏画面风格和赛车的操控感都将有较大的改变。《优品飞车13:变速》是《优品飞车》系列转型之后推出的首批作品当中的次世代版。本作不再由过去的Black Box工作室开发,而是交给了Slightly Mad工作室。Slightly Mad工作室专以开发赛车游戏见长。
测试结果
《优品飞车13》显然对于这些怪兽级显卡来说只是小菜一碟,所有显卡都能在最高分辨率+8XAA的情况下流畅体验该游戏,不过经过精减过的GTX465明显比GTX470成绩要差。
物理加速游戏----Batman: Arkham Asylum《蝙蝠侠:阿甘疯人院》
Batman: Arkham Asylum《蝙蝠侠:阿甘疯人院》
Eidos Interactive、华纳兄弟互动娱乐和NVIDIA公司共同宣布,由DC Comics公司授权的《蝙蝠侠:阿甘疯人院》Windows PC版本支持NVIDIA PhysX技术,提供超逼真的临场体验,加上游戏中充满高度互动性的物件,带领玩家进入蝙蝠侠在纽约市罪犯精神病院中的惊险搏斗。
测试结果
蝙蝠侠:阿甘疯人院是一款NVIDIA的物理加速游戏,不具Physx物理加速技术的A卡与具备物理加速技术的N卡没有可比性。
物理加速游戏----Dark Void《黑暗虚空》
Dark Void《黑暗虚空》
今年伊始卡普空代理发行了一款名为《Dark Void》(黑暗虚空)的游戏,制作单位是曾经帮微软开发过《血色苍穹》游戏的Airtight Games工作室,制作单位名气并不大,这样的游戏要想获得玩家的认可必须要有一些绝活,他们的选择是支持PhysX和APEX技术,游戏中的爆炸、烟雾以及碎片效果因此比以往的物理游戏更为强悍,制作方试图以提高玩家的互动性的方式作为突破口打开玩家的大门。
测试平台
同样是一款物理加速游戏,N卡仍然是有着绝对的优势。
物理加速&DX11游戏----METRO 2033《地铁2033》
METRO 2033《地铁2033》
本作题材基于俄罗斯最畅销小说Dmitry Glukhovsky。由乌克兰4A游戏工作室开发,采用4A游戏引擎,而且PC版支持nvidia的PhysX物理特效。 2013年,世界被一次灾难性事件毁灭,几乎所有的人类都被消灭,而且地面已经被污染无法生存,极少数幸存者存活在莫斯科的深度地下避难所里,人类文明进入了新的黑暗时代。直至2033年,整整一代人出生并在地下成长,他们长期被困在“地铁站”的城市。
测试结果
地铁2033是一款十分变态的游戏,支持DX11的同时,还支持了Physx物理加速技术。所以N卡有着直接优势。
DirectX11 DEMO----StoneGiant《石巨人》
StoneGiant《石巨人》
游戏引擎开发商BitSquid和游戏开发商Fatshark今日宣布,已为PC游戏爱好者准备了一款用于检验GPU之DX11能力的技术演示程序,名为“StoneGiant”。
测试结果
《石巨人》DEMO即可感觉到里面夸张的几何多变型使用率,每样物体每一个细节都做得非常细腻,十分考验显卡的几何生成能力。专门针对几何计算而优化架构的GF100在这测试里肯定占尽优势。
DirectX11游戏----Colin McRae DiRT 2《 科林麦克雷:尘埃2 》
Colin McRae DiRT 2《 科林麦克雷:尘埃2 》
作为全球首款支持DirectX 11的赛车游戏,《尘埃2》使用的EGO引擎整体部署DirectX 11技术,支持图形多线程、硬件Tessellation以及SM5.0等新特性,更注重沙尘和赛车的表现效果,无论是飘沙的设计,还是在车道上留下的车痕都体现的淋漓尽致。另外,据悉本作还针对车辆内的操作人员动作也做了强化,让玩家亲身体验赛车的刺激。
测试结果
尘埃2是一款大量采用了曲面细分技术的游戏。在游戏版本更新和驱动的更新后,A卡和N卡的游戏表现水平相等。
DirectX11游戏----S.T.A.L.K.E.R.: Call of Prypiat《潜行者:普里皮亚季的召唤》
S.T.A.L.K.E.R.: Call of Prypiat《潜行者:普里皮亚季的召唤》
《S.T.A.L.K.E.R:普里皮亚季召唤》采用GSC的X-Ray图形引擎开发,并且支持DirectX 11。游戏故事发生在《切尔诺贝利的阴影》的故事之后,普里皮亚季是乌克兰的一个城镇名字,是切尔诺贝利事件的隔离区,它是一座被废弃的城市,具体在乌克兰首都基辅以北的区域,民间有“鬼城”之称,现时Pripyat市已经成为了一个旅游景点。
测试结果
《潜行者:晴空》是唯一一个ATI HD5800系列全面超员GTX470/465的项目,这归咎于GSC Game World是ATI铁杆伙伴,从DX9到DX10.1再到DX11,GSC Game World一直都和ATI进行紧密的合作开发游戏。
DirectX11游戏----Battlefield: Bad Company 2《叛逆连队2》
Battlefield: Bad Company 2《叛逆连队2》
《战地:叛逆连队2》(Battlefield: Bad Company 2),是EA DICE开发的一款第一人称射击游戏。该作是EA DICE开发的第9款“战地”系列作品,也是《战地:叛逆连队》的直接续作,在继承前作特性的基础上,加强了多人联机载具对战和团队合作元素的设定。游戏使用加强版的寒霜引擎,加入了建筑物框架破坏和物体分块破坏的支持。
测试结果
近期颇受欢迎的《战地:叛逆连队2》是大家比较看重的游戏,NVIDIA与ATI的表现影响到众多玩家日后升级电脑体验叛逆连队2的重要依据。GTX400系列明显在该游戏中性价比更高
DirectX11游戏----Aliens vs Predator《异形大战铁血战士》
Aliens vs Predator《异形大战铁血战士》
《异形大战铁血战士(Aliens vs. Predator)》是一部很经典的老游戏,于1999年首次在PC上推出,以其恐怖的故事情节和血腥的镜头受到媒体和玩家的关注。十年后的今天借助于高科技的游戏制作技术,《异形大战铁血战士(Aliens vs. Predator)》实现了高超的画面和多样的游戏模式,势必会给新老玩家带来惊喜。
测试结果
异形大战铁血战士是一款比较血腥的游戏,并不是每一个人都喜欢。由于和A家的密切合作关系,所以对A卡的优化比较好,所以在游戏中,A卡的游戏性能表现会比较好。
NVIDIA游戏DEMO:Realistic Character Hair
Realistic Character Hair
Character Hair是针对NVIDIA即将发布的Fermi显卡做了优化,其功能就是为了测试NVIDIA DriectX 11显卡的细分曲面技术。由于人像的头发能够随风而动是由Physics技术而生成的,所以人像的头发飘动自然而真实。在DEMO里可以不同角度的观看人像头发的动态效果,头发数量和曲面细分效果的强弱得到控制,实现实时的GPU渲染效果。
测试结果
NVIDIA游戏DEMO:Realistic Water&Terrain
Realistic Water&Terrain
大量的使用Tessseltion(曲面细分)技术
Water&Terrain同样是针对NVIDIA即将发布的Fermi显卡做了优化,其功能就是为了测试NVIDIA DriectX 11显卡的细分曲面技术,同样使用Physics技术生成的水动态的流动。由于可以大量的使用Tessseltion(曲面细分)技术,所以水面的细节比较逼真。
测试结果
NVIDIA游戏DEMO:RagingRapids(小船)
RagingRapids(小船)
RagingRapids此款游戏是专门为FERMI GPU而设计的Physx测试程序,小般行使过的水花溅射、旗帜的破坏和山上的滚石都是由Physx技术自帖控制和生成的。并且该程序还可以从GPU渲染马上切换到CPU渲染,实时看到Physx的强大运算及回事效果。
测试结果
NVIDIA游戏DEMO:SupersonicSled
SupersonicSled
SupersonicSled
SupersonicSled
SupersonicSled
SupersonicSled是NVIDIA根据Fermi显卡的特点而制作的一款demo,这款demo主要展示了Tessseltion(曲面细分)和Physx特效。
测试结果
NVIDIA游戏DEMO:RayTracing_DesignGarage
RayTracing_DesignGarage
RayTracing_DesignGarage
RayTracing这款Demo同样针对NVIDIA的Fermi显卡而推出的测试软件,这款Demo主要展示了显卡的光线追踪技术。在上代显卡中,光线追踪技术很早就被使用,虽然画面效果也十分精细,但其光线反射效果并不是通过实时运算产生,因此在物体运动时期表面的光影无法根据周围环境而变化。而最新的光线追踪技术则与现实更为接近,可以使物体表面根据周围环境产生不同的光影反射效果。
处理中效果:
光线追踪处理中
处理后效果:
光线追踪处理后效果
CUDA软件应用:Badaboom
Badaboom是读者都已经非常熟悉的一款软件了,这款软件伴随着CUDA技术的正式发布,目前还确实受到了很多NVIDIA 显卡用户的青睐。Badaboom主要应用在视频转换上,进行视频编码的操作我们平时经常用到,例如我们要将从网络上下载或者从DVD上获得的视频文件进行重新的编码压缩,才能传到我们手机、IPOD、iPhone以及PSP中观看。
Badaboom
经过笔者的测试,很大一部分视频格式都可以被BadaBoom支持,可以说所有编码格式的视频都能够支持。只不过互联网上有部分视频采用的非标准容器封装的,有可能导致BadaBoom不能正确识别。
Badaboom已经能支持GTX465
BadaBoom在目标视频的输出上可以直接支持数十种设备,即使这数十种分辨率中都没有你想要的,你还可以完全自定义视频分辨率,非常方便。不过需要提醒大家的是,BadaBoom是一款共享软件,从网上下载之后只有30次的试用期,过期后则必须购买正式版本。
而由于要进行和其他软件的对比测试,显然这样的模板设计不能满足我们要求。我们要具体指导它的码率、品质、音频品质等等,以保证和其他软件压缩一致性。
转码进行中。。。
转码完成
而从图片中看到,左侧一栏可以直接选择光驱中的光盘、浏览DVD中的对应文件,或者直接在硬盘上搜索需要压缩的文件,操作也非常方便。
CUDA软件应用:Folding@Home
Folding@home是斯坦福大学的一个分布式计算计划可以利用分布于全球的计算机模拟复杂的蛋白质折叠效应,是一款典型的科学计算程序。目前已经推出了支持CUDA环境的版本。该项目的客户端程序可以使用客户机的CPU或NVIDIA CUDA enable GPU对同一以项目进行求解,为了让大家最清楚的了解CUDA的GeForce系列GPU在科学计算方面与CPU和其他计算解决方案在性能上的区别。
测试结果
GTX465温度实测:
注:室温为22-26度
待机温度为44,满载温度为92
虽然在规格上GTX465相比GTX470有一定程度上的缩减,但40nm GF100架构的GPU芯片本身的发热量就比大,而且搭配的散热器风扇设定的转速比较低,所以在满载时候温度还是直接达到92度。
GTX465功耗实测:
Seasonic的Powerangel功率测试仪器
在功耗的对比方面,我们选择了Seasonic的Powerangel功率测试仪器进行平台的功耗对比(不包含光驱、显示器及其他周边配件和外设)即机箱内设备功耗。测试主要划分为闲置与满载两个项目,其中闲置主要是针对进入系统后闲置的状态下,而满载则针对的是FURMARK进行渲染平均功耗读数测试进行。测试在都关闭主板板载的CPU节能功能的环境下进行。
测试结果
面对着拥有出色功耗控制的HD5800系列显卡,GF100架构的GTX400系列的功耗控制明显的相对不够好,只能说HD5800的功耗控制真的很好。
超频测试:小超达GTX470水平
GTX465默认:
GTX465默认测试结果
GTX465超频:
超频后测试结果
超频测试,可以看到由于MSI超频软件的限制,笔记手头上的GTX465核心频率只能达到790Mhz,显存频率达到3998Mhz,性能提幅为高达28%。结合之前的同平台VANTAGE的测试,GTX465超频后的P18203已经达到了默认频率的GTX470水平。而且笔者深信,如果没有软件的限制GTX465的超频幅度会更高。
注:在截稿前,我们收到来自影驰的消息称,魔盘HD超频软件已经增加了对GTX465的支持。
总结:
GTX465目前作为NVIDIA针对高端的产品,采用Fermi显示核心,在架构上和GTX480和GTX470相同,同样支持DX11的所有特性。GTX465的流处理器减少到了352个流处理器,而性能上要比GTX470降低15%到20%,价钱上也要比GTX465便宜不少,而相对于竞争对手的HD5830,GTX470的性能能与其一较高下,彼此的性能也相当接近。
GTX465
GTX465的售价将是2188元,价格上的优势并不算明显,而HD5830价格是1999元,价位接近的HD5830也开始出现不少的非公版产品,价格的竞争能也比价大,而现在GTX480/GTX470也开始出现非公版的产品,此次首测我们已经收到GTX465非公版产品,非公版的GTX465售价要比公版的GTX465低,非公版的GTX465的出将会使得GTX465的价格进一步降低。
GF100核心
GTX465的出现可以帮助NVIDIA消化一部分Fermi的瑕疵芯片,另外更可以进一步向下层市场渗透,但是采用Fermi核心的成本并不低,而根据NVIDIA未来的DX11显卡的部署,可以看到GTX460和GTX465的规格相当接近,NVIDIA未来将会使用成本更低GTX460取代GTX465,而现时由于GTX285等的高端显卡的缺货,GTX465的出现只是权宜之计。
Fermi显卡
不论是权宜之计还是NVIDIA清理Fermi不良产品,GTX465的出现将Fermi架构继续向下层渗透,针对高端的GF100核心出现了三个不同的版本,2000元市场的GTX465性能上拥有非常出色的表现,GTX465也是NVIDIA将DX11产品渗透到中高端市场,也有力阻击对手的HD5830,NVIDIA将会在未来一段时间继续发布更多的DX11显卡,DX11的显卡大战也将会爆发。
索泰GTX465
索泰GTX465
索泰GTX465
索泰GTX465
索泰GTX465
GTX465外观
GTX465外观
GTX465正式发布了,各大厂商的GTX465也会陆续登陆市场,现在上市的GTX465都是采用公版设计,使用和GTX470一样的PCB和散热器,在供电接口方面也同样采用双6pin电源接口。
GTX465视频接口
影驰GTX465
影驰GTX465
影驰GTX465
影驰GTX465
影驰GTX465
影驰GTX465
影驰GTX465
影驰GTX465
七彩虹GTX465
七彩虹GTX465
七彩虹GTX465
七彩虹GTX465
七彩虹GTX465
七彩虹GTX465
七彩虹GTX465
映众GTX465
映众GTX465
映众GTX465
映众GTX465
映众GTX465
映众GTX465
映众GTX465
映众GTX465
双敏GTX465
双敏GTX465
双敏GTX465
双敏GTX465
双敏GTX465
双敏GTX465
双敏GTX465
旌宇GTX465
旌宇GTX465
旌宇GTX465
旌宇GTX465
旌宇GTX465
旌宇GTX465
旌宇GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465
耕昇非公版GTX465

