图形前端引擎
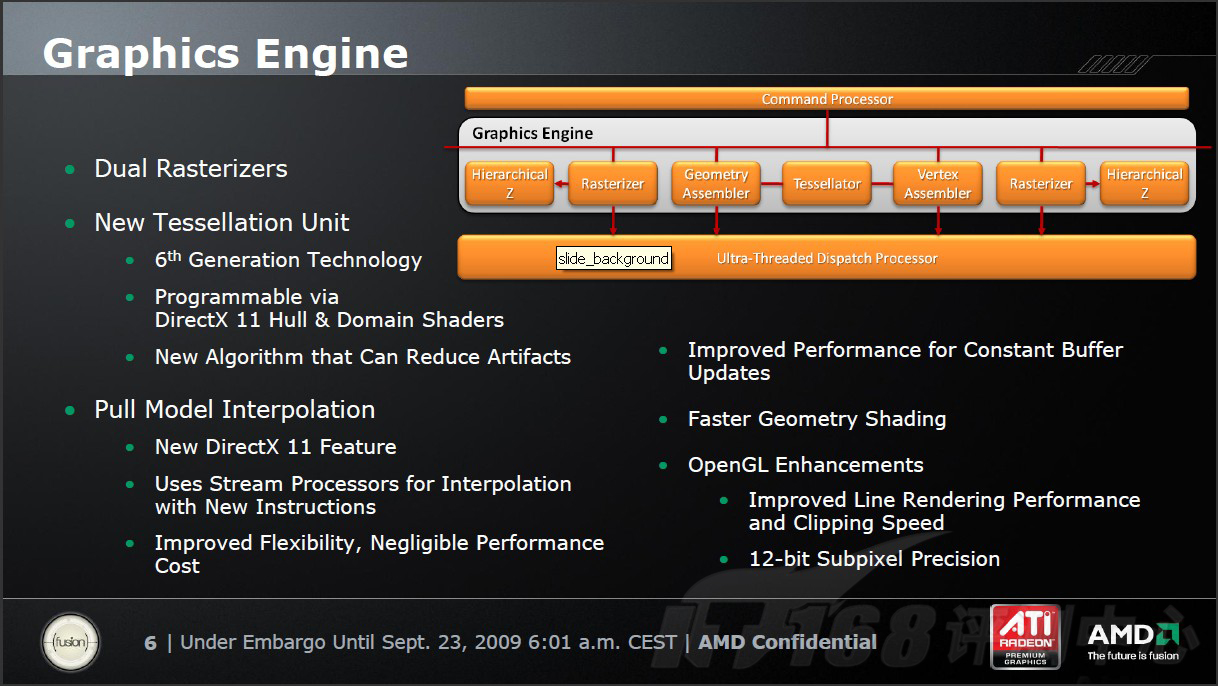
RV870上的这个Graphics Engine实际上就是RV7xx和RV6xx身上的Setup Engine的升级加强版。它由两个光栅化单元(Rasterizer),两个递阶Z(Hierarchical Z)、一个顶点装备器(Vertex Assembler)、一个集合装配器(Geometry Assembler)和一个拆嵌细分器(Tessellator)组成。
较之以前,区别比较大的就是这个Tessellation。全新的Tessellation已经是ATI产品线中的第六代Tessellation,支持DX11的同时,在效能上相对之前的版本也有相当的提高。关于Tessellation的有关详情,请参考我们前面在DX11简介中提到的相关内容。
线程处理器

在SIMD陈列规模扩大的同时,Ultra-Threaded Dispatch Processor(超线程分配处理器)也变得更加复杂。由于每组SIMD所包括的Shader数量增多,阵列内的Arbiter(仲裁器)和Sequencer(定序器)数量同比增加,目的就是为了确保扩充规模后,RV870单个Shader执行效率不会下降。
80个问题单元(Texture Units)

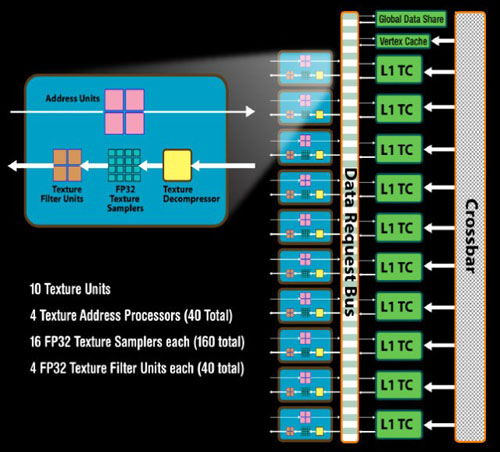
我们知道,R600/RV670/RV770的纹理单元内部结构实际上是相同的,但是2008年推出的RV770,其TMU的数量相比/R600RV670就已经翻了2.5倍,从4组增加至10组,这样,RV770总共就是40个纹理单元,Shader和TMU的比例达到了4:1。而RV870的SIMD阵列又从RV770的10组激增到20组,那么相应的,RV870总共就是80个纹理单元,SIMD Shader和TMU的比例仍为4:1。
RV770
关于RV870问题单元部分的细节,AMD暂时没有给出明确数据,以下的数据,参考RV770得到:每组纹理单元内部包含了4个纹理寻址单元(粉红色,共80个),16个32位浮点纹理采样单元(浅蓝色,共320个),4个纹理过滤单元(橙色,共80个),1个纹理解压单元(黄色,共20个)。
再来看看细节部分,可以看到8个黄色的纹理寻址单元和20个FP32纹理采样单元还要区分大小,这是因为顶点着色只能使用到其中4个小纹理寻址单元进行纹理采样,而像素/几何着色则可以使用全部的8个;顶点着色只能使用其中4个小FP32纹理采样单元,而像素/几何着色则可以使用全部的20个。
全新的纹理过滤算法

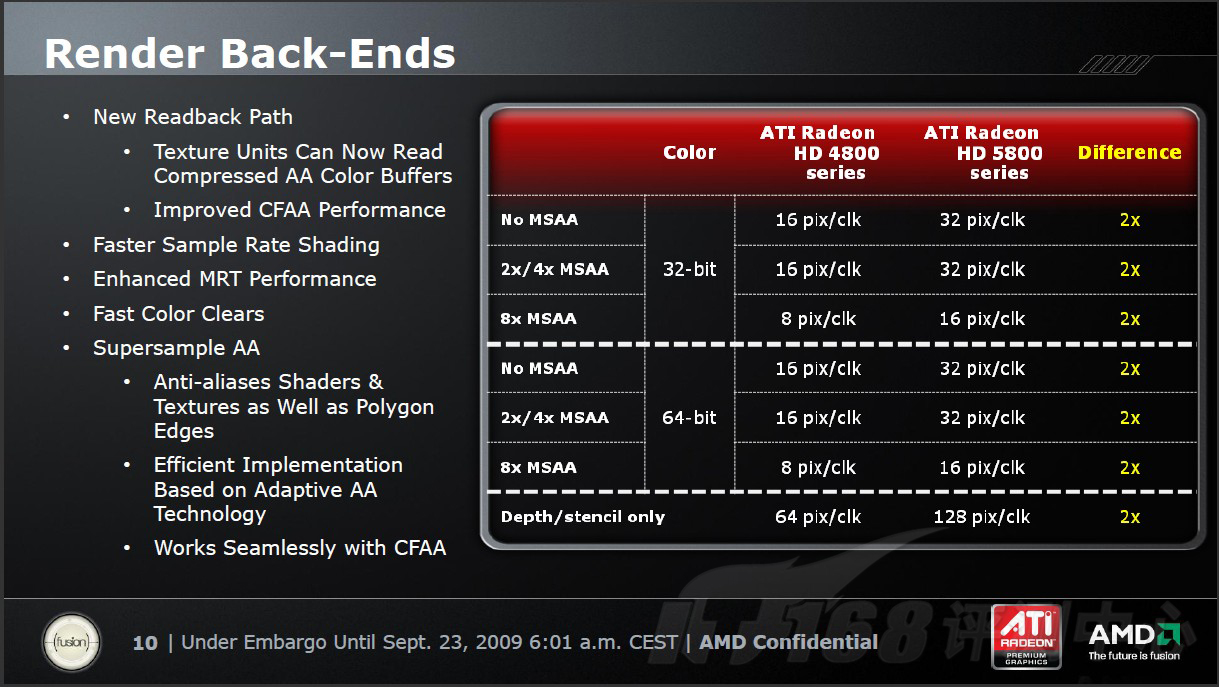
AMD的RBE(Render Back-Ends)等同于NVIDIA的ROP,都是负责光栅化像素输出及抗锯齿等后期处理任务,也是4×4架构,因此通常认为R600/RV670和G92一样包括16个ROPs。RV870的每个ROP可以在一个时钟周期内采样32个Z/模版,而且深度/模版是分开处理的,执行效率更高。从上一代RV770几乎免费提供2xMSAA来看,在RV870上实现真正的Free 4xMSAA甚至8xMSAA也不是不可能。这一点,将在我们后面的测试部分为大家解答。
下面,是AMD提供的一张4xMSAA和8xMSAA性能损失比较表。
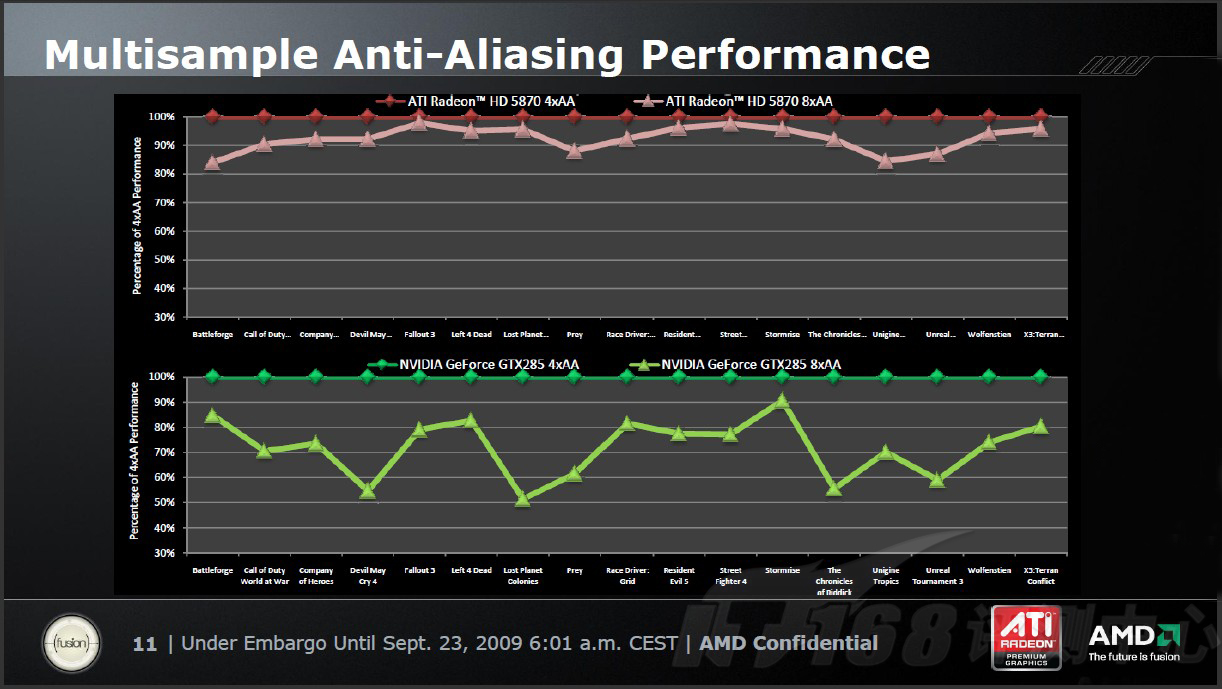
从图中可以很明显的看出,相比nVIDIA目前最强单核显卡GeForce GTX 285,基于RV870核心的Radeon HD 5870,从4xMSAA提高到8xMASS时,性能损失仅仅为1%-20%。相同情况下,GeForce GTX 285的性能损失达到了10%-50%。因此,可以明确的是,在高分辨率高画质高倍AAS情况下,RV870有着比GT200好得多的性能表现。对于骨灰级玩家来说,无需置疑的是,现阶段ATI提供了更优的决绝方案。
显存控制界面
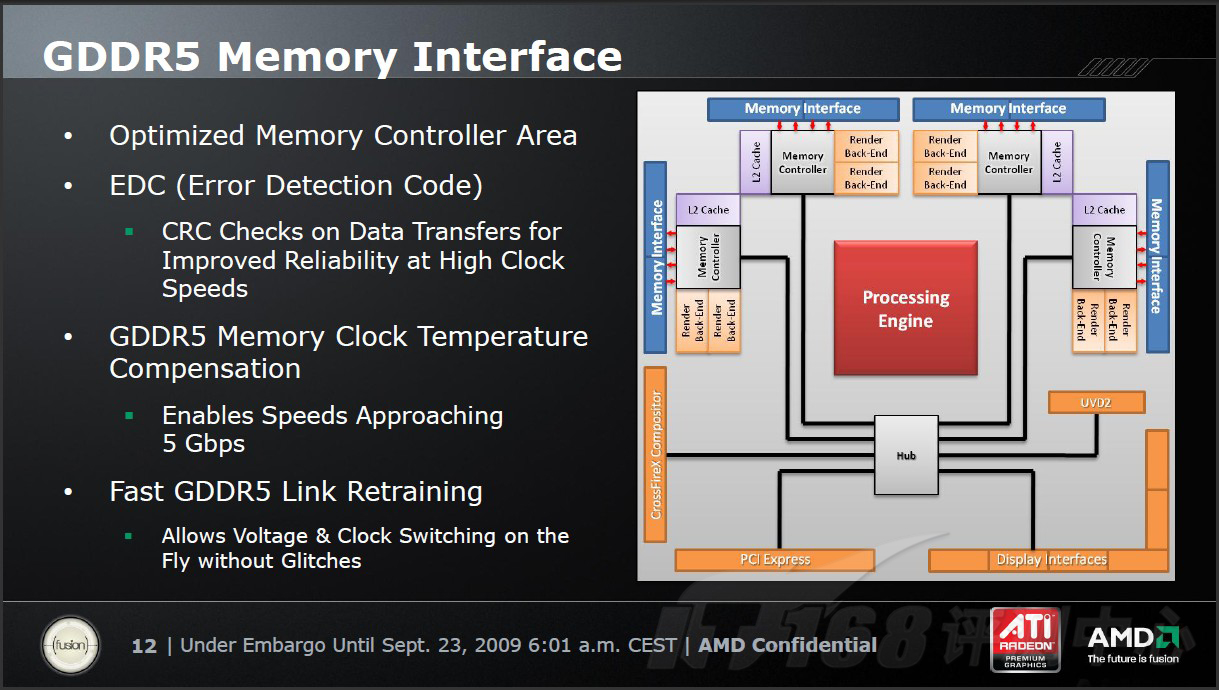
同RV770的4870和RV790的4890一样,RV870的Radeon HD 5870采用了GDDR5的显存界面,同时AMD还对显存控制器区域进行了细微的优化和调整。值得一提的是,AMD此次强调Radeon HD 5870采用的GDDR5是第二代,原因在于它支持错误校正代码,能够在数据传输的时候进行CRC校验,提高了GDDR5显存的哦高频稳定性和准确性。
关于目前ATI产品的显存控制器到底是RingBus还是CrossBar的问题,笔者想在这里强调一下:不管RingBus,还是CrossBar,他们的最终目的都是为了合理控制显存和核心的数据交换,力求最短路径、最低延迟、最高效率。因此,不管是RingBus还是CrossBar都只是一种实现形式,它们各有优劣。目前GPU的发展,显存控制器形式带来的性能影响,远没有显存位宽来得直接、明显。简言之,笔者想说的是,2005年X1800XT上诞生的RingBus,放在今天看也已经是相当“老成”的技术了,没有什么技术壁垒。AMd方面没有详细公布数,我们也不必就此问题深究。因为,它们的形式到底是什么,已经不重要了。
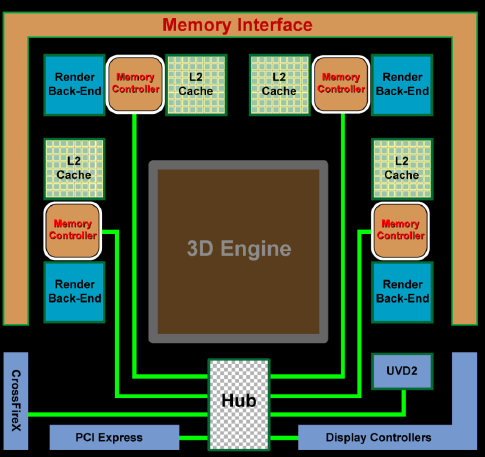
可以看到,与RV770的这部分相比,RV870并没有什么本质的变化,只是上端的RBE和L2 Cache位置有所微调,相互调换,其它部分基本相同。
AMD-ATI的“流计算”
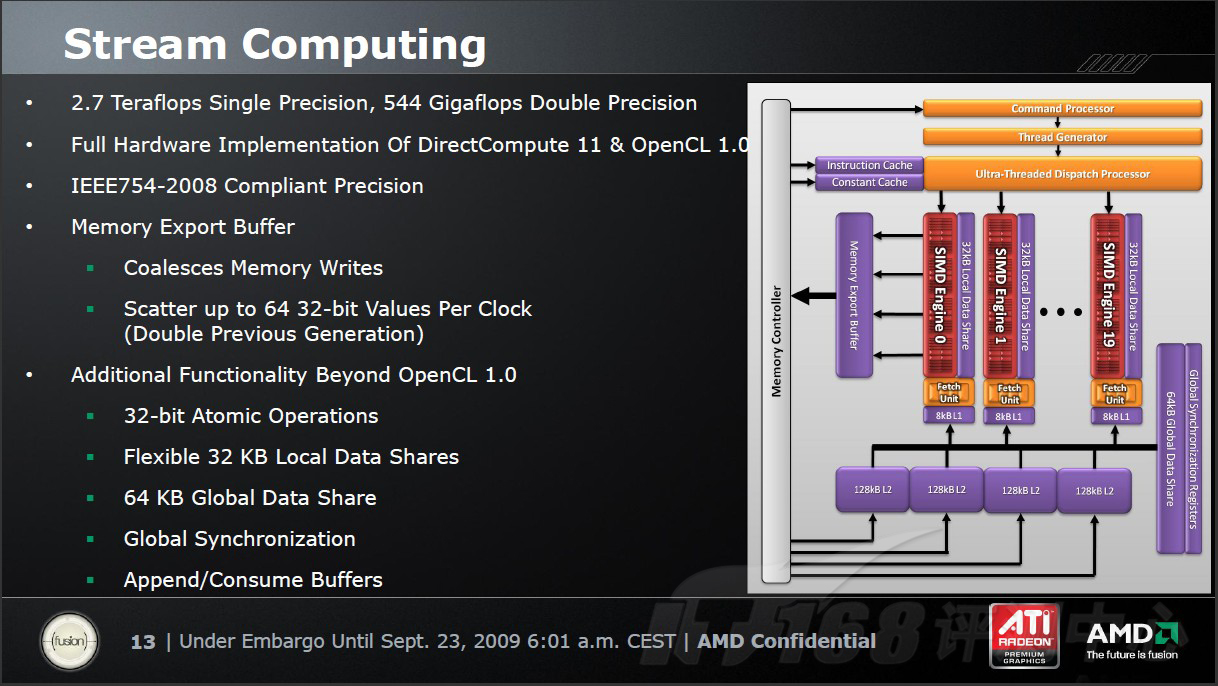
AMD-ATI Radeon HD 5870的浮点计算能力达到了惊人的单精度2.7TFlops、双精度544GFlops,这个速度几乎是NVIDIA Tesla C1060(GT200架构)的七倍之多。同时,RV870还提高了每时钟循环的指令数(IPC)。

